
Tìm hiểu mọi thứ bạn cần biết về phân tích dữ liệu khám phá, quy trình quan trọng được sử dụng để khám phá các xu hướng và mẫu cũng như tóm tắt các bộ dữ liệu bằng tóm tắt thống kê và biểu diễn đồ họa.
Giống như bất kỳ dự án nào, dự án phân tích dữ liệu là một quá trình dài đòi hỏi thời gian, tổ chức tốt và sự tôn trọng tỉ mỉ đối với một số bước. Phân tích dữ liệu thăm dò (EDA) là một trong những bước quan trọng nhất trong quy trình này.
Do đó, trong bài viết này, chúng ta sẽ xem xét ngắn gọn phân tích dữ liệu khám phá là gì và làm thế nào để thực hiện nó bằng R!
Phân tích dữ liệu khám phá là gì?
Phân tích dữ liệu khám phá khám phá và điều tra các đặc điểm của tập dữ liệu trước khi gửi nó tới một ứng dụng, cho dù thuần túy là kinh doanh, thống kê hay học máy.
Một bản tóm tắt như vậy về bản chất của thông tin và các đặc điểm chính của nó thường được thực hiện bằng các phương pháp trực quan như biểu diễn đồ họa và bảng. Việc thực hành được thực hiện trước một cách chính xác để đánh giá tiềm năng của những dữ liệu này, những dữ liệu này sẽ trải qua quá trình xử lý phức tạp hơn trong tương lai.
Do đó, EDA cho phép:
- Xây dựng các giả thuyết về việc sử dụng thông tin này;
- Xem chi tiết ẩn trong cấu trúc dữ liệu;
- Xác định các giá trị còn thiếu, ngoại lệ hoặc hành vi bất thường;
- Khám phá các xu hướng và các biến có liên quan nói chung;
- Loại bỏ các biến không liên quan hoặc các biến có tương quan với các biến khác;
- Chỉ định mô hình chính thức để sử dụng.
Sự khác biệt giữa phân tích dữ liệu mô tả và khám phá là gì?
Có hai loại phân tích dữ liệu, phân tích mô tả và phân tích dữ liệu khám phá, đi đôi với nhau mặc dù mục đích của chúng khác nhau.
Trong khi phần trước tập trung vào việc mô tả hành vi của các biến, ví dụ: giá trị trung bình, trung vị, chế độ, v.v.
Phân tích khám phá nhằm mục đích xác định mối quan hệ giữa các biến, trích xuất thông tin chi tiết ban đầu và mô hình hóa trực tiếp đến các mô hình học máy phổ biến nhất: phân loại, hồi quy và phân cụm.
Cùng nhau, cả hai có thể xử lý biểu diễn đồ họa; tuy nhiên, chỉ có phân tích khám phá nhằm cung cấp những hiểu biết sâu sắc có thể hành động, tức là những hiểu biết kích thích hành động của người ra quyết định.
Cuối cùng, trong khi phân tích dữ liệu khám phá nhằm mục đích giải quyết các vấn đề và đưa ra các giải pháp để hướng dẫn các bước lập mô hình, thì phân tích mô tả, như tên gọi của nó, chỉ nhằm mục đích tạo ra một mô tả chi tiết về một tập hợp dữ liệu nhất định.
Phân tích mô tả Phân tích dữ liệu thăm dò Phân tích hành vi Phân tích hành vi và các mối quan hệ Cung cấp bản tóm tắt Dẫn đến thông số kỹ thuật và hành động Tổ chức dữ liệu trong bảng và biểu đồ Tổ chức dữ liệu trong bảng và biểu đồ Không có khả năng giải thích đáng kể Có khả năng giải thích đáng kể
Một số ứng dụng thực tế của EDA
#1. tiếp thị kỹ thuật số
Tiếp thị kỹ thuật số đã phát triển từ quy trình sáng tạo sang quy trình dựa trên dữ liệu. Các tổ chức tiếp thị sử dụng phân tích dữ liệu khám phá để xác định kết quả của chiến dịch hoặc hoạt động và để hướng dẫn các quyết định nhắm mục tiêu và đầu tư của người tiêu dùng.
Nghiên cứu nhân khẩu học, phân khúc khách hàng và các kỹ thuật khác cho phép các nhà tiếp thị tận dụng một lượng lớn dữ liệu mua hàng, khảo sát và bảng điều khiển của người tiêu dùng để hiểu và truyền đạt chiến lược tiếp thị.
Web Exploratory Analytics cho phép các nhà tiếp thị thu thập thông tin cấp phiên về các tương tác trang web. Google Analytics là một ví dụ về công cụ phân tích phổ biến và miễn phí mà các nhà tiếp thị sử dụng cho mục đích này.
Các kỹ thuật khám phá thường được sử dụng trong tiếp thị bao gồm mô hình hóa tiếp thị hỗn hợp, phân tích giá cả và khuyến mãi, tối ưu hóa doanh số bán hàng và phân tích khách hàng khám phá, chẳng hạn như phân khúc.
#2. Phân tích danh mục đầu tư thăm dò
Một ứng dụng phổ biến của phân tích dữ liệu khám phá là phân tích thăm dò danh mục đầu tư. Ngân hàng hoặc cơ quan cho vay có một tập hợp các tài khoản có giá trị và rủi ro khác nhau.
Tài khoản có thể khác nhau tùy thuộc vào địa vị xã hội của chủ sở hữu (giàu, trung lưu, nghèo, v.v.), vị trí địa lý, giá trị ròng và nhiều yếu tố khác. Người cho vay phải cân bằng lợi tức của khoản vay với rủi ro vỡ nợ đối với mỗi khoản vay. Sau đó, câu hỏi đặt ra là làm thế nào để định giá toàn bộ danh mục đầu tư.
Khoản vay có rủi ro thấp nhất có thể dành cho những người rất giàu có, nhưng số người giàu có thì rất hạn chế. Mặt khác, nhiều người nghèo có thể vay, nhưng điều này khiến họ gặp nhiều rủi ro hơn.
Một giải pháp phân tích dữ liệu khám phá có thể kết hợp phân tích chuỗi thời gian với nhiều vấn đề khác để quyết định khi nào nên cho những phân khúc người vay khác nhau này vay tiền hoặc trả lãi cho khoản vay. Tiền lãi được tính cho các thành viên của một phân khúc danh mục đầu tư để bù lỗ giữa các thành viên của phân khúc đó.
#3. Phân tích rủi ro thăm dò
Các mô hình dự đoán trong ngân hàng được phát triển để mang lại sự tự tin trong đánh giá rủi ro cho khách hàng cá nhân. Điểm tín dụng được thiết kế để dự đoán hành vi tội phạm của một người và được sử dụng rộng rãi để đánh giá mức độ tín nhiệm của bất kỳ người nộp đơn nào.
Ngoài ra, phân tích rủi ro được thực hiện trong thế giới khoa học và ngành bảo hiểm. Nó cũng được sử dụng rộng rãi bởi các tổ chức tài chính, chẳng hạn như các công ty thanh toán trực tuyến, để phân tích xem một giao dịch là thật hay lừa đảo.
Với mục đích này, họ sử dụng lịch sử giao dịch của khách hàng. Nó được sử dụng phổ biến hơn để mua hàng bằng thẻ tín dụng; trong trường hợp khối lượng giao dịch của khách hàng tăng đột biến, khách hàng sẽ nhận được cuộc gọi xác nhận liệu anh ta có bắt đầu giao dịch hay không. Nó cũng giúp giảm tổn thất do những trường hợp như vậy gây ra.
Phân tích dữ liệu thăm dò với R
Điều đầu tiên bạn cần làm EDA từ R là tải xuống R base và R Studio (IDE), sau đó cài đặt và tải các gói sau:
#Installing Packages
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#Loading Packages
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
Đối với hướng dẫn này, chúng tôi sẽ sử dụng bộ dữ liệu kinh tế được tích hợp trong R và cung cấp các chỉ số kinh tế hàng năm cho nền kinh tế Hoa Kỳ và chúng tôi sẽ đổi tên nó thành eco cho đơn giản:
econ <- ggplot2::economics
Để thực hiện phân tích mô tả, chúng tôi sẽ sử dụng gói Skir, gói này tính toán các số liệu thống kê này theo cách đơn giản và được trình bày tốt:
#Descriptive Analysis skimr::skim(econ)

Bạn cũng có thể sử dụng chức năng tóm tắt để phân tích mô tả:
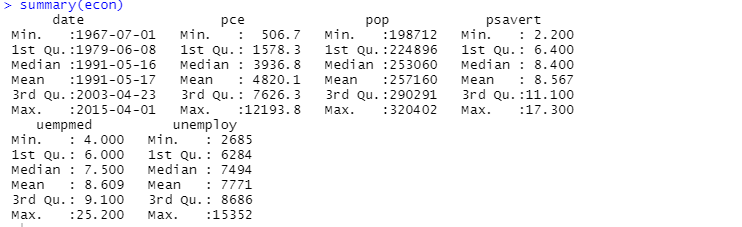
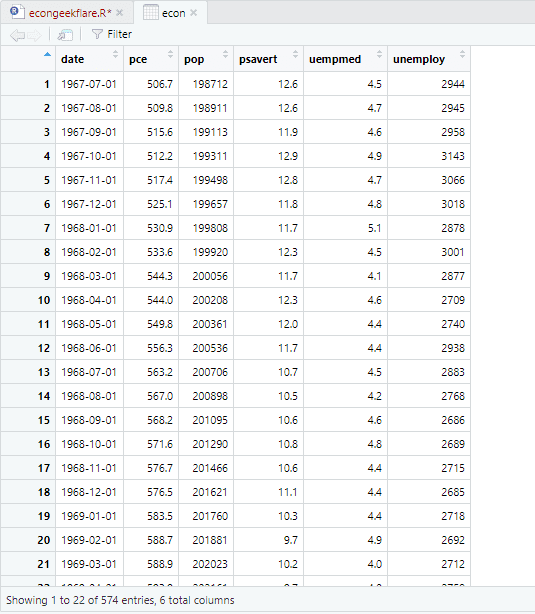
Ở đây phân tích mô tả cho thấy 547 hàng và 6 cột trong tập dữ liệu. Giá trị tối thiểu là 1967-07-01 và tối đa là 2015-04-01. Tương tự, nó cũng hiển thị giá trị trung bình và độ lệch chuẩn.
Bây giờ bạn đã có một ý tưởng cơ bản về những gì có trong bộ dữ liệu kinh tế. Hãy vẽ biểu đồ của biến để có cái nhìn rõ hơn về dữ liệu:
#Histogram of Unemployment econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015")
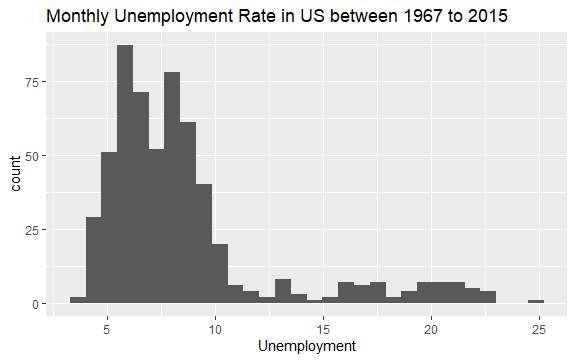
Phân phối biểu đồ cho thấy nó có một cái đuôi dài ở bên phải; điều này có nghĩa là có thể có một số quan sát của biến này với nhiều giá trị “cực đoan” hơn. Câu hỏi đặt ra: những giá trị này diễn ra trong thời kỳ nào và xu hướng của biến là gì?
Cách trực tiếp nhất để xác định xu hướng của một biến là sử dụng biểu đồ đường. Dưới đây chúng tôi tạo một biểu đồ đường và thêm một đường làm mịn:
#Line Graph of Unemployment econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
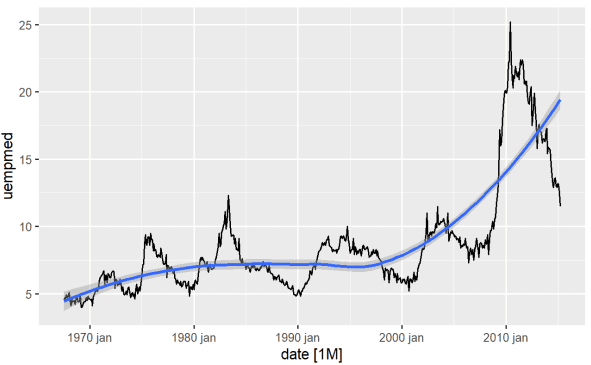
Sử dụng biểu đồ này, chúng ta có thể kết luận rằng trong giai đoạn gần đây, theo các quan sát cuối cùng từ năm 2010, có xu hướng gia tăng tỷ lệ thất nghiệp, vượt quá lịch sử quan sát được trong các thập kỷ trước.
Một điểm quan trọng khác, đặc biệt là trong bối cảnh mô hình kinh tế lượng, là tính dừng của chuỗi; nghĩa là, giá trị trung bình và phương sai có liên tục theo thời gian không?
Khi các giả định này không đúng với một biến, chúng ta nói rằng chuỗi có gốc đơn vị (không cố định) để các cú sốc đối với biến tạo ra hiệu ứng lâu dài.
Có vẻ như đây là trường hợp của biến được thảo luận – thời gian thất nghiệp. Chúng tôi thấy rằng sự dao động của biến số đã thay đổi đáng kể, điều này có ý nghĩa mạnh mẽ đối với các lý thuyết kinh tế về chu kỳ. Nhưng rời xa lý thuyết, làm thế nào để bạn thực tế kiểm tra xem một biến có dừng không?
Gói dự đoán có một tính năng tuyệt vời để sử dụng các thử nghiệm như ADF, KPSS và các thử nghiệm khác đã trả về số lượng chênh lệch cần thiết để làm cho chuỗi đứng yên:
#Using ADF test for checking stationarity forecast::ndiffs( x = econ$uempmed, test = "adf")

Ở đây giá trị p lớn hơn 00,05 cho thấy dữ liệu không cố định.
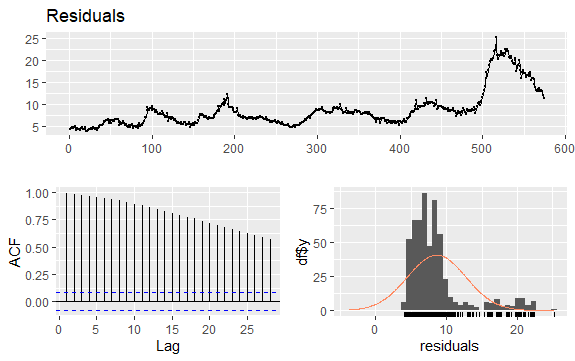
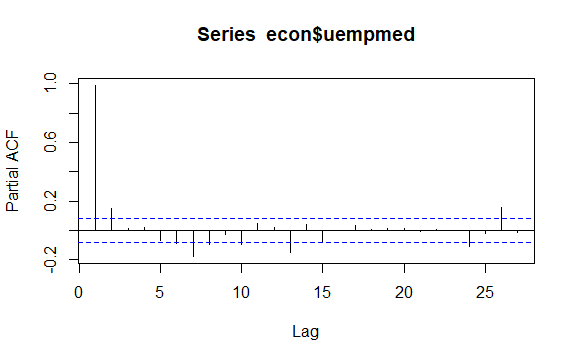
Một vấn đề quan trọng khác trong chuỗi thời gian là việc xác định các mối tương quan có thể có (mối quan hệ tuyến tính) giữa các giá trị trễ của chuỗi. Biểu đồ tương quan ACF và PACF giúp xác định nó.
Vì chuỗi không theo mùa mà có một số xu hướng, tự tương quan ban đầu có xu hướng lớn và dương vì các quan sát gần thời gian cũng có giá trị tương tự.
Do đó, hàm tự tương quan (ACF) của chuỗi thời gian có xu hướng có giá trị dương giảm dần khi độ trễ tăng dần.
#Residuals of Unemployment checkresiduals(econ$uempmed) pacf(econ$uempmed)
Đăng kí
Khi chúng ta có trong tay dữ liệu sạch ít nhiều, nghĩa là đã được làm sạch, ngay lập tức nảy sinh sự cám dỗ để đi sâu vào giai đoạn xây dựng mô hình để đưa ra những kết quả đầu tiên. Bạn cần chống lại sự cám dỗ này và bắt đầu thực hiện phân tích dữ liệu khám phá, đơn giản nhưng giúp chúng tôi hiểu rõ hơn về dữ liệu.
Bạn cũng có thể xem các tài nguyên tốt nhất để tìm hiểu về thống kê khoa học dữ liệu.
