
Trang web này có thể có được hoa hồng liên kết từ các liên kết trên trang này. Điều khoản sử dụng  Chips nóng 31 đang được tiến hành trong tuần này, với các bài thuyết trình từ một số công ty. Intel đã quyết định sử dụng một hội nghị kỹ thuật cao để thảo luận về một số sản phẩm, bao gồm các phiên chính tập trung vào bộ phận trí tuệ nhân tạo của công ty. Trí thông minh nhân tạo và học máy được coi là lĩnh vực quan trọng cho tương lai của điện toán và mặc dù Intel đã quản lý các lĩnh vực này bằng các tính năng như DL Boost trong Xeon, nhưng nó cũng chế tạo máy gia tốc dành riêng cho thị trường.
Chips nóng 31 đang được tiến hành trong tuần này, với các bài thuyết trình từ một số công ty. Intel đã quyết định sử dụng một hội nghị kỹ thuật cao để thảo luận về một số sản phẩm, bao gồm các phiên chính tập trung vào bộ phận trí tuệ nhân tạo của công ty. Trí thông minh nhân tạo và học máy được coi là lĩnh vực quan trọng cho tương lai của điện toán và mặc dù Intel đã quản lý các lĩnh vực này bằng các tính năng như DL Boost trong Xeon, nhưng nó cũng chế tạo máy gia tốc dành riêng cho thị trường.
NNP-I 1000 (Spring Hill) và NNP-T (Spring Crest) dành cho hai thị trường khác nhau, suy luận và đào tạo. "Đào tạo" là công việc tạo và dạy một mạng lưới thần kinh cách xử lý dữ liệu ngay từ đầu. Suy luận đề cập đến nhiệm vụ thực sự thực hiện một mô hình mạng thần kinh hiện đang được đào tạo. Cần nhiều sức mạnh tính toán hơn để đào tạo một mạng lưới thần kinh hơn là áp dụng các kết quả đào tạo vào một nhiệm vụ phân loại hoặc phân loại trong thế giới thực.
Intel Spring Crest NNP-T được thiết kế để phát triển ở mức độ chưa từng có, với sự cân bằng giữa khả năng xử lý tenor, gói HBM, dung lượng mạng và SRAM tích hợp để cải thiện hiệu suất xử lý. Con chip cơ bản được chế tạo bởi TSMC, vâng, TSMC, ở 16nm, với kích thước ma trận là 680 mm2 và một interleaver 1200 mm2. Bộ phận hoàn chỉnh có 27 tỷ bóng bán dẫn với ngăn xếp bộ nhớ HBM2-2400 4x8GB, 24 nhóm xử lý tenor (TPC) với tần số lõi lên đến 1, 1GHz. Sáu mươi bốn dòng HSIO SerDes cung cấp băng thông tổng hợp 3, 58Tbps và thẻ hỗ trợ kết nối PCIe x16 4.0. Công suất tiêu thụ được ước tính trong khoảng 150-250W. Con chip này được xây dựng bằng gói CoWoS TSMC (Chip-on-wafer-on-Substrate) tiên tiến và vận chuyển 60 MB bộ nhớ cache được phân phối trong một số lõi. CoWoS cạnh tranh với Intel EMIB, nhưng Intel đã quyết định xây dựng phần cứng này trên TSMC thay vì sử dụng xưởng đúc của riêng mình. Sản lượng được ước tính là 119 TOPS.
"Chúng tôi không muốn lãng phí khu vực vào những thứ chúng tôi không cần", Phó chủ tịch Intel Phần cứng Carey Kloss nói với Next Platform. "Tập lệnh của chúng tôi rất đơn giản; nhân ma trận, đại số tuyến tính, tích chập. Chúng tôi không có hồ sơ riêng, chúng đều là các thang đo (2D, 3D hoặc 4D)." Có nhiều thứ được định nghĩa trong phần mềm, bao gồm khả năng lập trình những gì tương tự khi phá vỡ mô hình để thực hiện hoặc tắt xúc xắc. "Hãy nghĩ về nó như một hệ thống phân cấp," Kloss nói trong cuộc phỏng vấn. "Bạn có thể sử dụng cùng một bộ hướng dẫn để di chuyển dữ liệu giữa hai nhóm trong một nhóm bên cạnh HBM hoặc giữa các nhóm hoặc thậm chí chết trên mạng. Chúng tôi muốn đơn giản hóa rằng phần mềm quản lý giao tiếp."
Trình chiếu dưới đây cho thấy các bước của kiến trúc NNP-T. Tất cả dữ liệu thuộc về Intel và các số liệu hiệu suất được chia sẻ trong microbenchmark của công ty rõ ràng chưa được ExtremeTech xác nhận.

NNP-T được thiết kế để thoát ra hiệu quả mà không cần khung gầm. Nhiều máy gia tốc NNP-T có thể được kết nối trong cùng một khung và các thẻ hỗ trợ khung máy với khung và thậm chí các kết nối không rõ ràng từ giá này sang giá khác mà không cần chuyển đổi. Có bốn cổng mạng QFSP (Quad Small Form Factor Pluggable) ở mặt sau của mỗi thẻ trung gian.
Chúng tôi vẫn chưa có dữ liệu hiệu suất, nhưng đây là thẻ đào tạo cao cấp mà Intel sẽ tiếp thị để cạnh tranh với những người như Nvidia. Hiện vẫn chưa rõ các giải pháp cuối cùng, như Xe, sẽ không được giao cho các trung tâm dữ liệu cho đến năm 2021, sẽ đưa vào danh mục sản phẩm trong tương lai của công ty sau khi có bộ xử lý GPU và căng thẳng trên thị trường trung tâm dữ liệu.
Spring Hill / NNP-I: Icelake trên tàu
Spring Hill, máy gia tốc suy luận mới của Intel, là một động vật hoàn toàn khác. Nếu NNP-T được thiết kế cho các phong bì công suất 150-250W, thì NNP-I là phần 10-50W dự định kết nối với khe M.2. Nó có hai lõi CPU Koreake được ghép nối với 12 Công cụ tính toán suy luận (ICE).
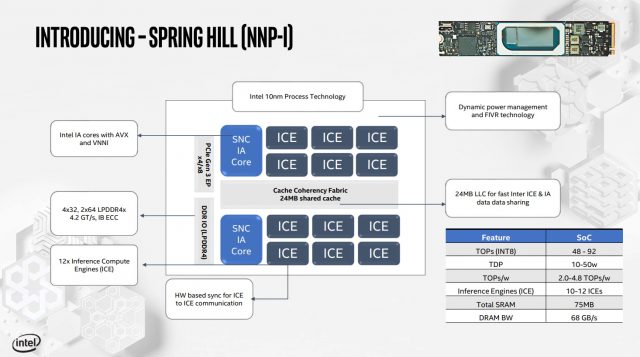
Máy A12 ICE và lõi CPU kép tương thích với LMB nhất quán là 24 MB và tương thích với các hướng dẫn AVX-512 và VNNI. Có hai bộ điều khiển bộ nhớ LPDDR4X tích hợp được kết nối với nhóm bộ nhớ LPDDR4 đã chết (chưa biết gì về dung lượng). Băng thông DRAM lên tới 68GB / giây, nhưng tổng số lượng DRAM trên thẻ là không xác định. Spring Hill có thể được thêm vào bất kỳ máy chủ hiện đại nào hỗ trợ các khe M.2 – Theo Intel, thiết bị liên lạc qua thang máy M.2 như các sản phẩm PCIe thay vì thông qua NVMe.
Mục tiêu, với NNP-I, là thực hiện các hoạt động trong bộ xử lý AI với ít chi phí yêu cầu của CPU chính trong sistema. Thiết bị được kết nối thông qua PCIe (cả PCIe 3.0 và 4.0 tương thích) và xử lý khối lượng công việc AI, sử dụng lõi ma trận của Koreake để xử lý cần thiết. SRAM và DRAM trong mảng cung cấp băng thông bộ nhớ cục bộ.
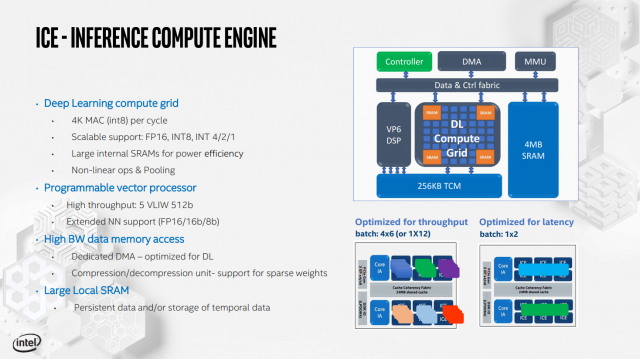
Inference Compute Engine hỗ trợ nhiều định dạng hướng dẫn, từ FP16 đến INT1, với bộ xử lý vector lập trình và 4 MB SRAM cho từng ICE riêng lẻ.
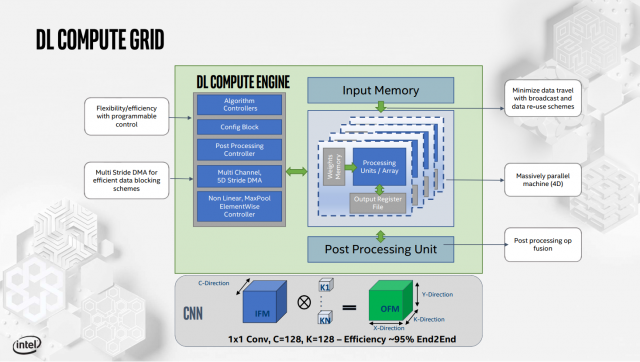
Ngoài ra còn có một động cơ căng, được gọi là Deep Learning Compute Grid và Tensilica Vision P6 DSP (được sử dụng để xử lý khối lượng công việc không được điều chỉnh để chạy trên DL Computing Grid tính toán cố định).
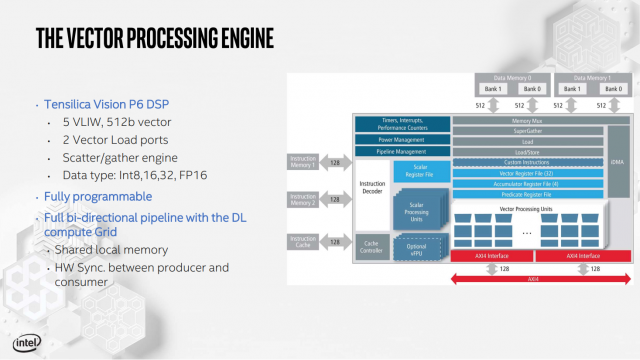
Toàn bộ hệ thống con bộ nhớ NNP-I cũng được tối ưu hóa, với bộ đệm L3 được chia thành tám phân đoạn 3 MB, được phân chia giữa lõi ICE và CPU. Mục tiêu là giữ dữ liệu càng gần càng tốt với các yếu tố xử lý cần chúng. Intel tuyên bố rằng NNP-I có thể cung cấp rất nhiều hiệu năng ResNet50 3.600 suy luận mỗi giây khi chạy trên TDP 10W. Nó làm việc cho đến khi 4,8 TOPS / Watt, đáp ứng các mục tiêu hiệu quả tổng thể của Intel (công ty tuyên bố rằng NNP-I hiệu quả hơn với công suất thấp hơn).
Intel không hy vọng NNP-I sẽ tiếp cận thị trường bán lẻ, nhưng các giải pháp suy luận làm kinh doanh nhanh chóng so với các giải pháp đào tạo trung tâm đào tạo cao cấp. NNP-Tôi có thể được gửi cho một số khách hàng trong một thời gian ngắn, tùy thuộc vào mức độ hấp thụ chung.
Cả hai giải pháp đều nhằm thách thức Nvidia trong trung tâm dữ liệu. Mặc dù hai loại này rất khác so với Xeon Phi, nhưng bạn có thể lập luận rằng chúng đang cùng nhau hướng đến một không gian mà Intel Xeon Phi muốn bán, mặc dù theo một cách rất khác. Nhưng điều đó không phải lúc nào cũng xấu: khi Larrabee ban đầu được chế tạo, ý tưởng sử dụng GPU cho công việc trí tuệ nhân tạo và trung tâm dữ liệu là một khái niệm mạnh mẽ. Xem xét các vấn đề với kiến trúc đặc biệt mới để suy luận và đào tạo là một bước đi thông minh của Intel, nếu công ty có thể lấy khối lượng của Nvidia.
Bây giờ đọc:
