
Trang web này có thể kiếm được hoa hồng liên kết từ các liên kết trên trang này. Điều khoản sử dụng. 
Có rất ít cuộc trò chuyện về lý do tại sao điều này xảy ra, nhưng Karl Freund của Moor Insights and Strateg đã nắm bắt được tin tức. Theo ông, Intel sẽ hỗ trợ NNP-I cho các khách hàng đã cam kết trước đó, trực tiếp nhưng sẽ ngừng mọi sự phát triển trên thiết kế đào tạo AI của NNP-T.
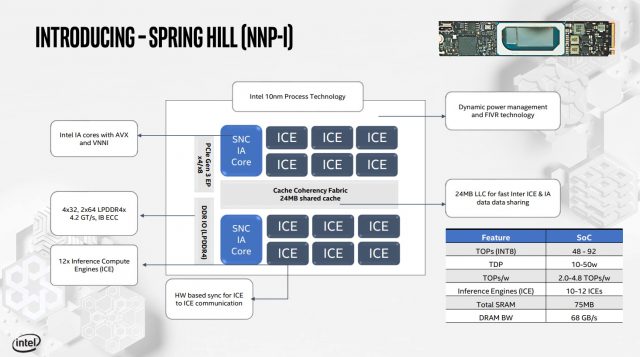
NNP-T được thiết kế tại TSMC và dành cho quy trình FinFET 16nm của công ty đó và phù hợp với các phong bì công suất 150-250W. NNP-I, rõ ràng sẽ được hỗ trợ ở một mức độ nhỏ, là một phần 10-50W kết hợp hai lõi CPU Ice Lake với 12 công cụ tính toán suy luận (ICE).
Suy nghĩ ở đây là phần cứng của Nervana, không phải có hiệu năng cạnh tranh đặc biệt với những gì đối thủ của Intel có hoặc đang mang ra thị trường. Intel có một loạt các sản phẩm nhắm đến nhiều AI khác nhau, tìm hiểu sâu và tính toán thị trường với Mobileye, Movidius, kiến trúc Xe sắp ra mắt và kinh doanh đồ họa. Habana Labs đã vận chuyển Bộ xử lý suy luận Goya của mình kể từ quý 4 năm 2018 và Bộ xử lý đào tạo AI của Gaudi đã lấy mẫu của khách hàng để chọn khách hàng vào nửa cuối năm 2019. Quyết định của Intel về việc đóng cửa công việc tiếp theo trên kiến trúc Nervana sẽ xuất hiện.
Đây là nỗ lực học máy AI / máy thứ hai mà Intel đã ngừng hoạt động, sau Xeon Phi, nhưng tôi không chắc chắn tôi đã đọc được bao nhiêu. Xeon Phi là một nỗ lực để tạo ra một sản phẩm dựa trên x86 mới có thể cạnh tranh với GPU với khối lượng công việc chính xác gấp đôi. Các sự cố 10nm của Intel đã ngăn công ty đẩy Xeon Phi xuống các nút thấp hơn, nhưng gốc rễ của kiến trúc bắt nguồn từ thử nghiệm GPU của Larrabee đã thất bại, không phải là bất kỳ nỗ lực quyết tâm nào để xây dựng bộ xử lý AI / ML.
Việc hủy bỏ các sản phẩm của Nervana, chắc chắn đã tác động mạnh đến các nhóm sản phẩm đó, nhưng chúng tôi vẫn còn rất sớm trong trò chơi AI, và rất nhiều công ty hiện đang làm việc trên các máy gia tốc thế hệ đầu tiên. Việc Goya có mặt trên thị trường và Gaudi đã lấy mẫu trước khi Intel mua công ty cung cấp một số đảm bảo rằng nhà sản xuất CPU giành chiến thắng phải dành một lượng lớn thời gian để đưa một phần ban đầu ra thị trường.
AI và máy học đã được Nvidia và Intel làm trung tâm cho đến tận bây giờ, và xu hướng đó dường như sẽ tiếp tục trong tương lai gần. Sự hiện diện của AMD trên các thị trường này – và khả năng cạnh tranh hiệu quả thông qua các dự án dịch thuật như ROCm, so với hỗ trợ bản địa cho Nvidia CUDA – đều khiêm tốn so với các đối thủ lớn nhất của nó.
Công bằng mà nói với AMD, đó không phải là một tai nạn. Khi các nhà phân tích hỏi liệu AMD có nhắm mục tiêu rõ ràng vào không gian AI / ML mới nổi hay không, các giám đốc điều hành của AMD nói chung nói rằng họ sẽ làm như vậy theo một cách hạn chế và với các sản phẩm cụ thể khi có ý nghĩa. AMD không thực hiện bất kỳ nỗ lực nào để nhắm mục tiêu các CPU như Epyc 7742 cho khối lượng công việc AI theo cách Intel tập trung vào việc hỗ trợ AVX-512 cho Xeon.
Năm 2020 sẽ là một năm đáng kể cho thị trường AI / ML. Lần lặp đầu tiên của người tiêu dùng GPU Intel Intel sẽ được tung ra thị trường trong năm nay. Mặc dù những thứ này rõ ràng sẽ dành cho các hệ thống chính thống, bạn có thể đặt cược rằng các nhà phân tích sẽ để mắt tới bất kỳ tính năng hoặc khả năng thân thiện với trung tâm dữ liệu nào có thể xuất hiện sớm. Các GPU 7nm thế hệ tiếp theo của Nvidia dự kiến sẽ giảm trong năm nay, cũng như AMD, Navi 20. Thật điên rồ khi nghĩ Navi 20 có thể tăng tốc cho GPU máy chủ, máy trạm hoặc GPU trung tâm dữ liệu mới của AMD trong năm nay.
Nói tóm lại, xoay quanh Habana và tránh xa Nervana không nhất thiết có nghĩa là Intel bị tụt lại phía sau – không lâu khi hiệu suất và lộ trình của Habana đã phù hợp với khách hàng của Intel hơn so với những gì họ đã bảo vệ trước đây.
Hãy đọc ngay bây giờ:
