
Hãy cùng tìm hiểu cách bạn có thể duy trì độ tin cậy của sản xuất bằng các công cụ Chaos Engineering.
Kỹ thuật hỗn loạn là một nguyên tắc mà bạn thử nghiệm trên hệ thống hoặc ứng dụng của mình để khám phá những điểm yếu và lỗi khả năng của nó. Đây là điều bạn không nghĩ có thể xảy ra trong quá trình phát triển. Vì vậy, bạn sẽ cố tình gây ra một số sự cố trong hệ thống của mình để phơi bày các điểm yếu của nó nhằm thực hiện các bản sửa lỗi cũng như làm cho hệ thống và ứng dụng của bạn trở nên linh hoạt hơn.
Nhiều tổ chức nổi tiếng như Netflix, LinkedIn và Facebook, thực hiện kỹ thuật hỗn loạn để hiểu rõ hơn về kiến trúc vi dịch vụ và các hệ thống phân tán của nó. Nó giúp tìm ra các vấn đề mới sớm hơn so với khiếu nại của người dùng thực và thực hiện các hành động cần thiết để khắc phục chúng. Bằng cách này, các tổ chức này có thể phục vụ hàng triệu người dùng, tăng năng suất và tiết kiệm hàng triệu đô la 🤑.
Lợi ích của kỹ thuật hỗn loạn:
- Kiểm soát tổn thất doanh thu bằng cách tìm ra các vấn đề quan trọng
- Giảm lỗi hệ thống hoặc ứng dụng
- Trải nghiệm người dùng tốt hơn với ít gián đoạn hơn và tính sẵn sàng của dịch vụ cao
- Nó giúp bạn biết hệ thống và có được sự tự tin.
Bạn tự tin đến mức nào về độ tin cậy sản xuất của mình? Nó thực sự là bằng chứng thảm họa?
Hãy cùng tìm hiểu với các công cụ kiểm tra hỗn loạn phổ biến sau đây.
lưới hỗn loạn
Chaos Grid là một giải pháp quản lý kỹ thuật hỗn loạn đưa ra lỗi cho mọi lớp của hệ thống Kubernetes. Điều này bao gồm Pods, Network, System I/O và Kernel. Chaos Mesh có thể tự động tắt các nhóm Kubernetes và mô phỏng độ trễ. Nó có thể cản trở giao tiếp giữa các thiết bị và mô phỏng lỗi đọc/ghi. Có thể lập kế hoạch các quy tắc của các thí nghiệm và xác định phạm vi của chúng. Các thử nghiệm này được chỉ định bằng các tệp YAML.
Chaos Mesh có một bảng điều khiển để xem phân tích thử nghiệm. Nó chạy trên Kubernetes và hỗ trợ hầu hết nền tảng đám mây. Nó là mã nguồn mở và gần đây đã được chấp nhận như một dự án hộp cát CNCF. Bằng cách sử dụng các nguyên tắc kỹ thuật hỗn loạn, bạn có thể thêm Chaos Mesh vào quy trình làm việc DevOps của mình để xây dựng các ứng dụng linh hoạt.
Tính năng kỹ thuật hỗn loạn:
- Dễ dàng triển khai các cụm Kubernetes mà không cần sửa đổi logic triển khai
- Không có phụ thuộc duy nhất được yêu cầu để triển khai
- Xác định các đối tượng hỗn loạn với CustomResourceDefinitions (CRD)
- Cung cấp bảng điều khiển để theo dõi tất cả các thử nghiệm
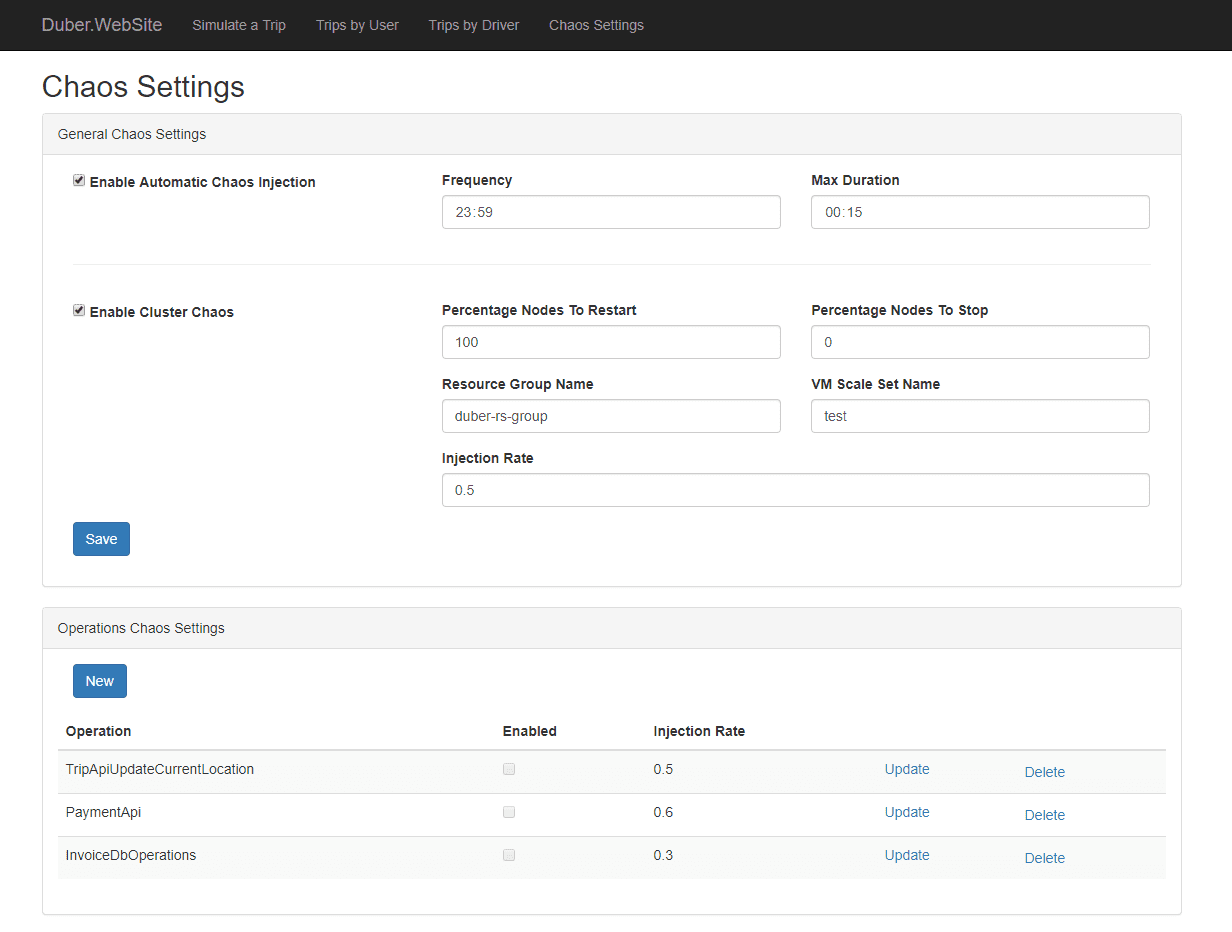
Bộ công cụ Chaos là một công cụ mã nguồn mở và đơn giản để tự động hóa các thí nghiệm kỹ thuật Chaos.
Bạn tích hợp Chaos ToolKit vào hệ thống của mình với một bộ trình điều khiển hoặc plugin hỗ trợ AWS, Google Cloud, Slack, Prometheus, v.v.
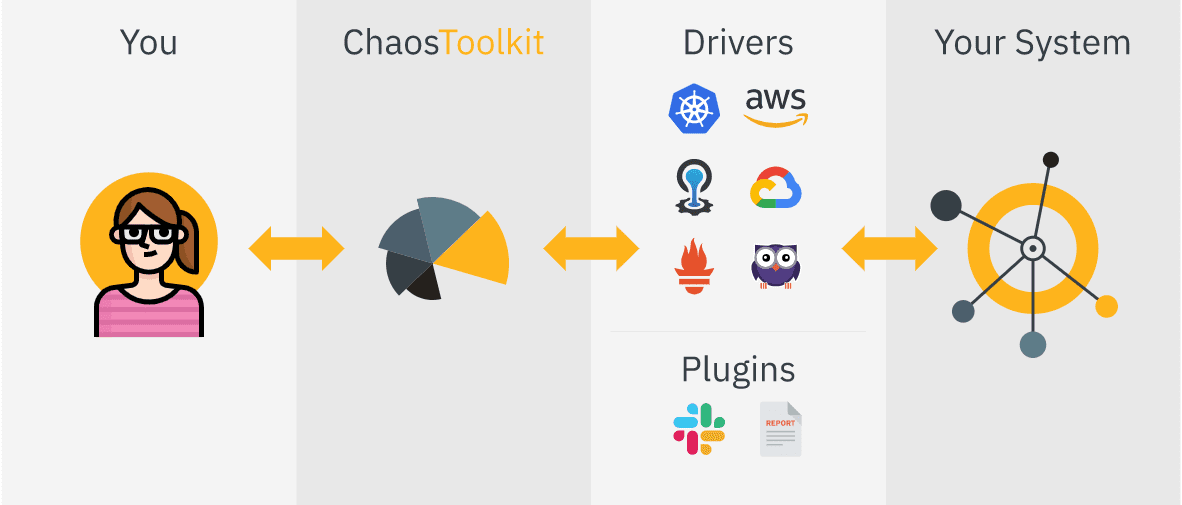
Các tính năng của Bộ công cụ hỗn loạn:
- Cung cấp API mở khai báo để tạo các thử nghiệm hỗn loạn bất kể nhà cung cấp hay công nghệ
- Có thể dễ dàng nhúng vào đường ống CICD để tự động hóa
- Nó cũng cung cấp hỗ trợ thương mại và doanh nghiệp thông qua: ChaosIQ
ChaosKube
Như bạn có thể đoán từ cái tên, nó dành cho Kubernetes.
Chaoskube là một công cụ hỗn loạn mã nguồn mở, định kỳ giết các nhóm ngẫu nhiên trong cụm Kubernetes. Nó giúp bạn hiểu hệ thống của bạn sẽ phản ứng như thế nào khi nhóm bị lỗi. Theo mặc định, nó sẽ giết nhóm trong bất kỳ không gian tên nào sau mỗi 10 phút. Bạn có thể lọc các nhóm mục tiêu trong Chaokube theo không gian tên, nhãn, chú thích, v.v. Chúng rất dễ cài đặt với Chaokube.

khỉ hỗn loạn
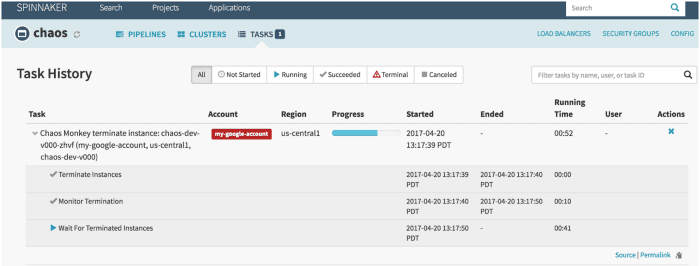
Chaos Monkey là một công cụ được sử dụng để kiểm tra khả năng phục hồi của các hệ thống đám mây bằng cách cố ý tạo ra các lỗi để các hệ thống đó có thể hiểu cách chúng phản ứng. Netflix đã tạo ra nó để kiểm tra khả năng phục hồi và khả năng phục hồi của cơ sở hạ tầng AWS. Nó được đặt tên là Chaos Monkey vì nó tạo ra sự hủy diệt giống như một con khỉ hoang dã và được trang bị vũ khí để thử nghiệm những thất bại.
Chính Chaos Monkey đã tạo ra phương pháp kỹ thuật mới của Chaos Engineering. Nó được tạo ra theo nguyên tắc thà thất bại nhiều lần để tránh thất bại nghiêm trọng đột ngột.
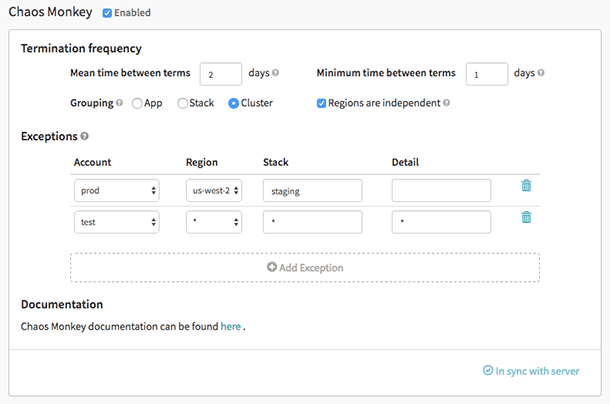
Đặc điểm của Chaos Monkey:
- Giúp bạn chuẩn bị cho các trường hợp lỗi ngẫu nhiên.
- Khuyến khích dự phòng trong trường hợp thất bại bất ngờ
- Nó sử dụng Spinnaker để đảm bảo khả năng tương thích giữa các đám mây
- Cung cấp lịch trình mô phỏng sự cố có thể định cấu hình
- Được tích hợp với thống đốc để thêm các phụ thuộc mới vào khỉ hỗn loạn
simmy
Simmy là một công cụ hỗn loạn chèn lỗi tích hợp với Dự án khả năng phục hồi Polly cho .NET. Cho phép bạn tạo các quy tắc hỗn loạn thông qua Polly nơi bạn thực thi mã của mình. Nó cung cấp các chính sách khác nhau như chính sách ngoại lệ để đưa các ngoại lệ vào hệ thống, chính sách hành vi để đưa vào hành vi mới, v.v. Các chính sách này được thiết kế để đưa vào hành vi một cách ngẫu nhiên.
Các tính năng Simma:
- Cung cấp quy tắc Khỉ hoặc quy tắc Chaos để tạo ra sự hỗn loạn
- Dễ dàng kiểm tra bất kỳ lỗi phụ thuộc nào
- Nó giúp nhanh chóng quay trở lại mô hình làm việc và kiểm soát bán kính vụ nổ.
- Nó đã sẵn sàng để sản xuất.
- Có thể xác định lỗi cũng dựa trên các yếu tố bên ngoài (ví dụ: lỗi do cấu hình chung)
súng lục
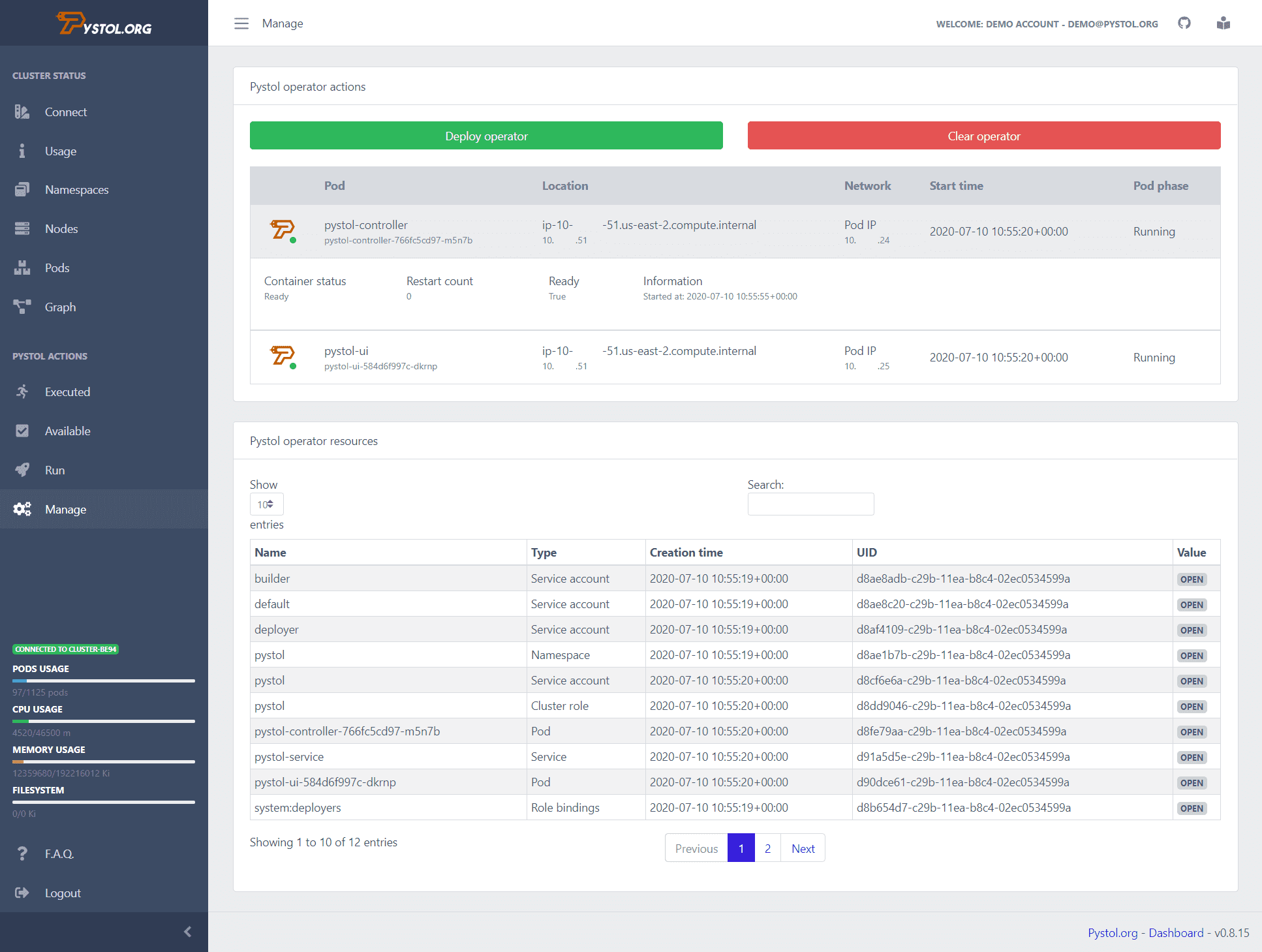
Súng lục là một công cụ được sử dụng để tiêm các mũi tiêm bị lỗi trong môi trường dựa trên đám mây. Quan sát các sự kiện trong ETCD thông qua các toán tử Kubernetes. Sau khi thực hiện hành động chèn lỗi, người vận hành tạo nhóm và chạy một số bộ sưu tập Ansible. Vì vậy, các lập trình viên không phải viết các hành động của riêng họ để thực thi.
Pystol cung cấp các hành động được tạo sẵn để thử nghiệm hệ thống. Tuy nhiên, nếu một lập trình viên muốn tạo một hành động mới, họ có thể làm như vậy bằng cách sử dụng GoLang và Python.
Nó cung cấp một bảng điều khiển tích hợp liên tục cung cấp bản tóm tắt tất cả các hoạt động liên quan đến công việc. Bạn có thể chạy Pistol cục bộ hoặc triển khai nó vào vùng chứa bằng hình ảnh docker của nó. Pystol cung cấp hai giao diện, một là Web UI và một là thông qua CLI. Tất nhiên, một giải pháp tốt hơn là giao diện web.
hỗn hợp
Muxy là một proxy để kiểm tra khả năng phục hồi và các mẫu khả năng chịu lỗi đối với các lỗi trong thế giới thực của các hệ thống phân tán. Có thể thao tác mức vận chuyển (lớp 4), mức phiên TCP (lớp 5) và cấp độ giao thức HTTP (lớp 7).
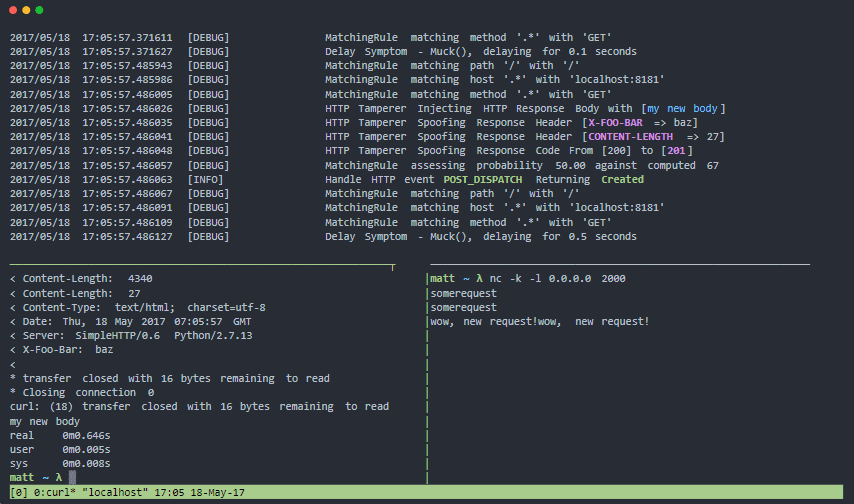
Các tính năng của Moxy:
- Kiến trúc mô-đun và dễ dàng mở rộng
- Nó có một container docker chính thức
- Dễ cài đặt, không cần phụ thuộc.
- Lý tưởng để kiểm tra sức đề kháng liên tục
- Mô phỏng các sự cố kết nối mạng cho các hệ thống phân tán và thiết bị di động
Pumbaa
Pumba là một công cụ dòng lệnh thực hiện kiểm tra hỗn loạn cho docker container. Với Pumbaa, bạn cố tình tạm dừng các bộ chứa docker của ứng dụng để xem hệ thống phản ứng như thế nào. Bạn cũng có thể thực hiện kiểm tra căng thẳng trên các tài nguyên vùng chứa như CPU, bộ nhớ, hệ thống tệp, I/O, v.v.
Bạn cũng có thể chạy Pumba trên cụm Kubernetes. Bạn cần sử dụng DaemonSets để triển khai Pumba trên các nút Kubernetes. Bạn có thể sử dụng nhiều bộ chứa Pumba để chạy nhiều lệnh Pumba trong cùng một DaemonSet.

Lưỡi kiếm hỗn loạn
Blade of Chaos là một công cụ mã nguồn mở để đưa các thử nghiệm vào các hệ thống của Alibaba. Nó kiểm tra tất cả những thất bại mà Alibaba đã gặp phải trong mười năm qua và áp dụng các phương pháp hay nhất để tránh chúng. Tuân theo các nguyên tắc của kỹ thuật hỗn loạn để kiểm tra khả năng phục hồi của các hệ thống phân tán.

Các tính năng của Chaos Blade:
- Cung cấp các kịch bản thử nghiệm cho nhiều tài nguyên như CPU, mạng, bộ nhớ, đĩa, v.v.
- Cung cấp các kịch bản thử nghiệm cho các nút, mạng và nhóm trên Kubernetes
- Nó cung cấp các lệnh CLI dễ sử dụng để thực hiện các thí nghiệm
quỳ tím
Litmus tuân theo các nguyên tắc kỹ thuật hỗn loạn dựa trên đám mây. Nhiệm vụ của công cụ Litmus là cung cấp một khung hoàn chỉnh để tìm kiếm các lỗ hổng trong hệ thống Kubernetes của bạn và chạy các ứng dụng Kubernetes.
Nó có một toán tử hỗn loạn và CRD (CustomResourceDefinitions) xung quanh nó, làm cho nó có thể cắm và chạy. Đó là về việc đưa logic hỗn loạn vào hình ảnh docker, ném nó vào cấu trúc giấy quỳ và sắp xếp chúng bằng CRD.

Các tính năng của quỳ:
- Giúp các kỹ sư và nhà phát triển độ tin cậy của trang web tìm thấy các lỗ hổng trong hệ thống Kubernetes
- Cung cấp các thử nghiệm chung sẵn sàng để sử dụng
- Cung cấp Chaos API để quản lý dòng chảy hỗn loạn
- SDK Litmus hỗ trợ Go, Python và Ansible để tạo thử nghiệm của riêng bạn.
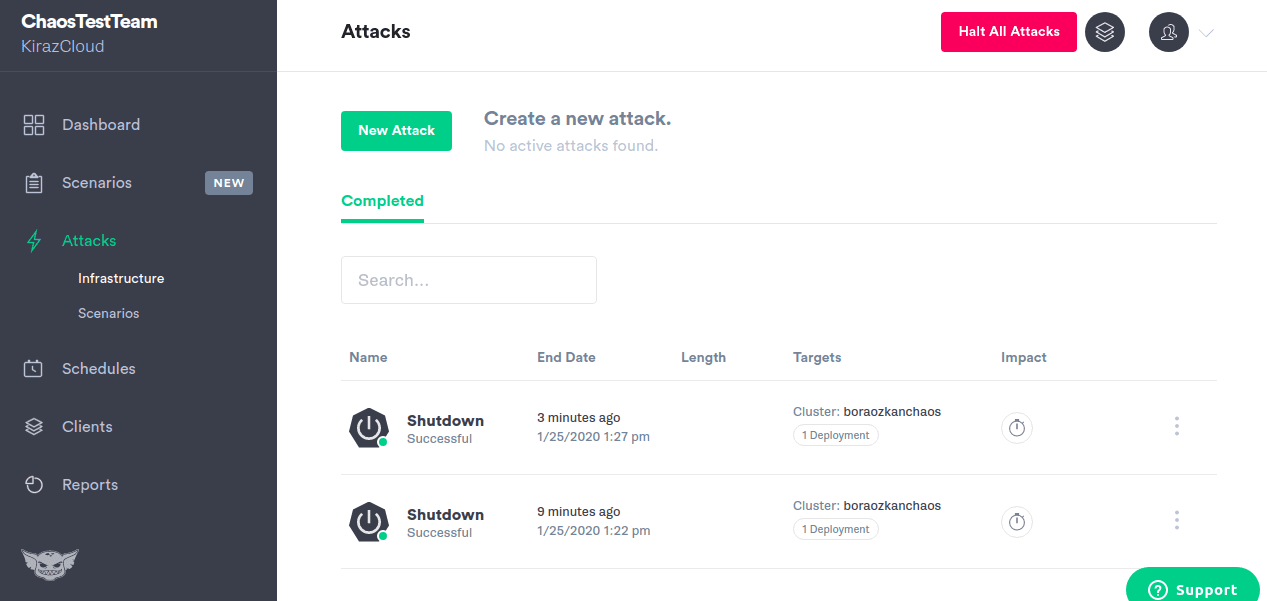
con ma xấu
Linh hồn xấu xa giúp các kỹ sư xây dựng phần mềm linh hoạt hơn. Nó cung cấp một nền tảng để tiến hành các thí nghiệm kỹ thuật hỗn loạn một cách an toàn và đơn giản.

Bạn có thể cố tình đưa lỗi vào máy chủ hoặc vùng chứa bằng gremlin, bất kể chúng được đặt ở đâu, có thể là đám mây công cộng hoặc trung tâm dữ liệu của riêng bạn.
Các tính năng của Gremlin:
- Cài đặt một tác nhân nhẹ trên máy chủ hoặc vùng chứa để đưa ra các lỗi
- Cung cấp hơn 10 chế độ tấn công cơ sở hạ tầng khác nhau
- Các gremlin trạng thái cho phép bạn điều khiển thời gian hệ thống, tắt hoặc khởi động lại máy chủ và tiêu diệt CPU.
- Gremlins mạng có thể gây ra sự chậm trễ để gây mất gói hoặc giảm lưu lượng.
- Các cuộc tấn công thư viện Gremlin Alfi có thể được định cấu hình, bắt đầu và dừng sử dụng ứng dụng web. API hoặc CLI
- Cho phép bạn nhắm mục tiêu chính xác chùm tia nổ mà bạn muốn tấn công
- Nó cho phép bạn ngăn chặn tất cả các cuộc tấn công và đưa hệ thống trở lại trạng thái ổn định
bit không đổi
Fixedbit được thiết kế để chủ động giảm thời gian chết và cung cấp thông tin chi tiết về các sự cố hệ thống. Bạn có thể chạy công cụ này cục bộ trên cơ sở hạ tầng của mình hoặc trên đám mây dưới dạng dịch vụ (SaaS).
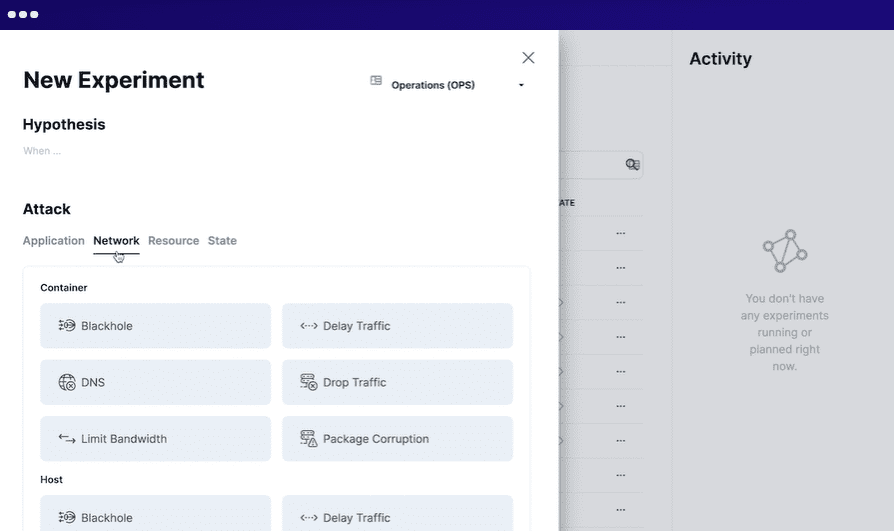
Để sử dụng Steadybit, bạn xác định tình huống, mô phỏng thử nghiệm, chạy thử nghiệm mô phỏng trên sản xuất và tự động hóa tất cả thử nghiệm. Chạy các tác nhân thông minh trên hệ thống để phát hiện các sự cố và lỗ hổng tiềm ẩn. Dễ dàng tích hợp với nhiều hệ thống.
Đăng kí
Hãy tiếp tục và đủ dũng cảm để áp dụng các nguyên tắc của kỹ thuật hỗn loạn và thử nghiệm quá trình sản xuất của bạn bằng các công cụ được đề cập ở trên. Những công cụ này sẽ giúp bạn tìm ra nhiều điểm yếu chưa được xác định trong hệ thống của mình và giúp bạn làm cho hệ thống trở nên linh hoạt hơn.
