
Apache Parquet cung cấp một số lợi thế về lưu trữ và truy xuất dữ liệu so với các phương pháp truyền thống như CSV.
Định dạng sàn gỗ được thiết kế để xử lý nhanh hơn các loại dữ liệu phức tạp. Trong bài viết này, chúng tôi nói về cách định dạng Parquet phù hợp với nhu cầu dữ liệu ngày càng tăng hiện nay.
Trước khi tìm hiểu chi tiết về định dạng Sàn gỗ, hãy hiểu dữ liệu CSV là gì và nó đặt ra những thách thức gì đối với việc lưu trữ dữ liệu.
Lưu trữ tệp CSV là gì?
Tất cả chúng ta đã nghe nhiều về CSV (Các giá trị được phân tách bằng dấu phẩy) – một trong những cách phổ biến nhất để sắp xếp và định dạng dữ liệu. Lưu trữ dữ liệu CSV dựa trên hàng. Các tệp CSV được lưu trữ với phần mở rộng .csv. Chúng tôi có thể lưu trữ và mở dữ liệu CSV bằng Excel, Google Trang tính hoặc bất kỳ trình soạn thảo văn bản nào. Dữ liệu có thể dễ dàng nhìn thấy khi bạn mở tệp.
Chà, điều đó không tốt – chắc chắn không dành cho định dạng cơ sở dữ liệu.
Hơn nữa, khi lượng dữ liệu tăng lên, việc truy vấn, quản lý và truy xuất trở nên khó khăn.
Dưới đây là một ví dụ về dữ liệu được lưu trữ trong tệp .CSV:
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
Nếu xem trên Excel, chúng ta có thể thấy cấu trúc hàng cột như sau:
Các thách thức về lưu trữ tệp CSV
Các cửa hàng dựa trên hàng như CSV phù hợp cho các thao tác tạo, cập nhật và xóa.
Còn Đọc trong CRUD thì sao?
Hãy tưởng tượng một triệu hàng trong tệp .csv ở trên. Sẽ mất một khoảng thời gian hợp lý để mở tệp và tìm kiếm dữ liệu bạn đang tìm kiếm. Không tốt lắm. Hầu hết các nhà cung cấp đám mây như AWS tính phí các công ty dựa trên lượng dữ liệu họ quét hoặc lưu trữ – một lần nữa, tệp CSV chiếm nhiều dung lượng.
Bộ lưu trữ CSV không có tùy chọn lưu trữ siêu dữ liệu độc quyền, điều này làm cho việc quét dữ liệu trở thành một công việc tẻ nhạt.
Vậy đâu là giải pháp tối ưu và tiết kiệm chi phí để thực hiện tất cả các thao tác CRUD? Hãy cùng khám phá.
Lưu trữ dữ liệu Parquet là gì?
Sàn gỗ là một định dạng lưu trữ mã nguồn mở để lưu trữ dữ liệu. Nó được sử dụng rộng rãi trong hệ sinh thái Hadoop và Spark. Các tệp sàn gỗ được lưu trữ với phần mở rộng .parquet.
Sàn gỗ là một định dạng có cấu trúc cao. Nó cũng có thể được sử dụng để tối ưu hóa dữ liệu thô phức tạp có số lượng lớn trong hồ dữ liệu. Điều này có thể làm giảm đáng kể thời gian truy vấn.
Sàn gỗ giúp lưu trữ dữ liệu hiệu quả và nhanh hơn bằng cách kết hợp các định dạng lưu trữ dựa trên hàng và dựa trên cột (kết hợp). Ở định dạng này, dữ liệu được phân vùng theo cả chiều ngang và chiều dọc. Định dạng sàn gỗ cũng loại bỏ phần lớn chi phí phân tích cú pháp.
Định dạng giới hạn tổng số hoạt động I/O và cuối cùng là chi phí.
Sàn gỗ cũng lưu trữ siêu dữ liệu lưu trữ thông tin dữ liệu như lược đồ dữ liệu, số lượng giá trị, vị trí cột, giá trị tối thiểu, số lượng nhóm hàng tối đa, loại mã hóa, v.v. Siêu dữ liệu được lưu trữ ở các cấp độ khác nhau trong tệp, tăng tốc độ truy cập dữ liệu.
Trong truy cập dựa trên hàng như CSV, sẽ mất một chút thời gian để tìm nạp dữ liệu vì truy vấn phải đi qua từng hàng và nhận các giá trị cột cụ thể. Nhờ có kho chứa sàn gỗ, tất cả các cột cần thiết đều có sẵn cùng một lúc.
Tóm tắt,
- Sàn gỗ dựa trên cấu trúc cột để lưu trữ dữ liệu
- Đây là một định dạng dữ liệu được tối ưu hóa để lưu trữ số lượng lớn dữ liệu phức tạp trong các hệ thống lưu trữ
- Định dạng sàn gỗ bao gồm các phương pháp nén và mã hóa dữ liệu khác nhau
- Giảm đáng kể thời gian quét dữ liệu và thời gian thực hiện truy vấn, đồng thời sử dụng ít dung lượng ổ đĩa hơn so với các định dạng lưu trữ khác như CSV
- Giảm thiểu số lượng hoạt động IO, giảm chi phí lưu trữ và thực hiện truy vấn
- Nó chứa siêu dữ liệu giúp dễ dàng tìm kiếm dữ liệu
- Cung cấp hỗ trợ mã nguồn mở
Định dạng dữ liệu sàn gỗ
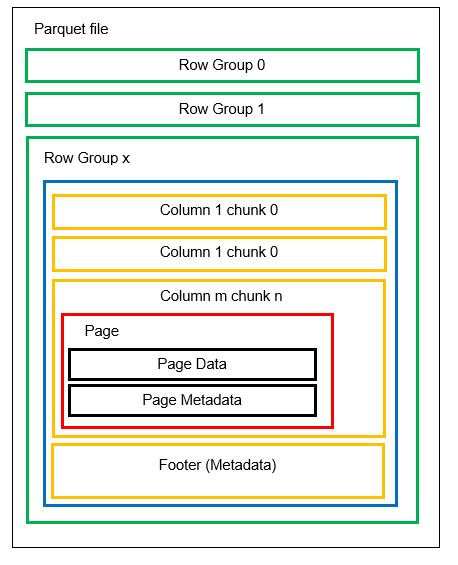
Trước khi lấy ví dụ, chúng ta hãy xem xét kỹ hơn cách dữ liệu được lưu trữ ở định dạng Parquet:
Chúng ta có thể có nhiều phân vùng ngang được gọi là nhóm hàng trong một tệp. Phân vùng dọc được áp dụng cho từng nhóm hàng. Các cột được chia thành nhiều đoạn cột. Dữ liệu được lưu trữ dưới dạng các trang bên trong các đoạn cột. Mỗi trang chứa các giá trị dữ liệu và siêu dữ liệu được mã hóa. Như đã đề cập trước đó, siêu dữ liệu của toàn bộ tệp cũng được lưu trữ ở phần cuối của tệp ở cấp nhóm hàng.
Vì dữ liệu được chia thành các khối cột nên việc thêm dữ liệu mới bằng cách mã hóa các giá trị mới vào một đoạn và tệp mới cũng rất dễ dàng. Sau đó, siêu dữ liệu được cập nhật cho các tệp và nhóm hàng bị ảnh hưởng. Do đó, có thể nói rằng Parkiet là một định dạng linh hoạt.
Sàn gỗ vốn hỗ trợ nén dữ liệu bằng kỹ thuật nén trang và mã hóa từ điển. Hãy xem một ví dụ đơn giản về nén từ điển:
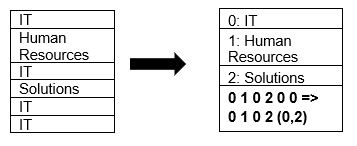
Lưu ý rằng trong ví dụ trên, chúng ta thấy sự cố CNTT 4 lần. Vì vậy, khi được lưu trữ trong từ điển, định dạng sẽ mã hóa dữ liệu bằng một giá trị dễ lưu trữ khác (0,1,2…) với số lần lặp lại liên tục – NÓ, NÓ đổi thành 0,2để tiết kiệm nhiều không gian hơn. Truy vấn dữ liệu nén mất ít thời gian hơn.
So sánh trực tiếp
Bây giờ chúng ta đã biết rõ định dạng CSV và Sàn gỗ trông như thế nào, đã đến lúc có một số thống kê để so sánh hai định dạng:
CSV
Sàn gỗ
Định dạng lưu trữ dựa trên hàng.
Kết hợp các định dạng lưu trữ dựa trên hàng và dựa trên cột.
Nó sử dụng rất nhiều dung lượng vì không có tùy chọn nén mặc định. Ví dụ, một tập tin có dung lượng 1 TB nó sẽ chiếm cùng một vị trí khi được lưu trữ trong Amazon S3 hoặc bất kỳ đám mây nào khác.
Nó nén dữ liệu trong quá trình lưu trữ để chiếm ít dung lượng hơn. tập tin dung lượng 1 TB được lưu ở định dạng Sàn gỗ, nó sẽ chỉ mất 130 GB vị trí.
Thời gian thực hiện truy vấn chậm do tìm kiếm theo hàng. Đối với mỗi cột, bạn phải tìm nạp từng hàng dữ liệu.
Thời gian truy vấn nhanh hơn khoảng 34 lần do lưu trữ dựa trên cột và sự hiện diện của siêu dữ liệu.
Cần quét thêm dữ liệu theo yêu cầu.
Ít hơn khoảng 99% dữ liệu được quét để thực hiện truy vấn, do đó tối ưu hóa hiệu suất.
Hầu hết các thiết bị lưu trữ tính phí dựa trên dung lượng có sẵn, vì vậy định dạng CSV có nghĩa là chi phí lưu trữ cao.
Chi phí lưu trữ thấp hơn do dữ liệu được lưu trữ ở định dạng nén, được mã hóa.
Lược đồ tệp phải được suy ra (dẫn đến lỗi) hoặc được cung cấp (nhàm chán).
Lược đồ tệp được lưu trữ trong siêu dữ liệu.
Định dạng phù hợp với các loại dữ liệu đơn giản.
Sàn gỗ thậm chí còn phù hợp với các loại phức tạp như lược đồ lồng nhau, mảng, từ điển.
Kết luận 👩 💻
Chúng ta đã thấy trong các ví dụ rằng Sàn gỗ hiệu quả hơn CSV về chi phí, tính linh hoạt và hiệu suất. Đó là một cơ chế hiệu quả để lưu trữ và truy xuất dữ liệu, đặc biệt là khi cả thế giới hướng tới lưu trữ đám mây và tối ưu hóa không gian. Tất cả các nền tảng chính như Azure, AWS và BigQuery đều hỗ trợ định dạng Parquet.
