

Nếu bạn đam mê thế giới trí tuệ nhân tạo, có thể bạn đã quen thuộc với GPT hoặc Máy biến áp được đào tạo trước. Không thể phủ nhận chúng là những mô hình xử lý ngôn ngữ tự nhiên ấn tượng được phát triển bởi OpenAI. Nói một cách đơn giản, những mô hình này vượt trội trong việc tạo ra văn bản giống con người dựa trên lời nhắc, điều hướng ngữ cảnh và thậm chí thể hiện sự sáng tạo.
Tuy nhiên, bạn có thể tò mò về sự khác biệt giữa các lần lặp lại khác nhau, từ GPT-1 thông qua GPT-4. Bài viết này sẽ giúp bạn hiểu những tiến bộ trong từng mô hình, bao gồm điểm mạnh, điểm yếu và ứng dụng chính của chúng. Tiến triển theo thời gian, OpenAI đã cho ra đời một loạt các mô hình này. Mỗi lần lặp mới kết hợp số lượng tham số lớn hơn, sau đó nâng cao hiệu suất của nó. Hãy cùng đi sâu vào so sánh các mẫu GPT này:
Đường dẫn nhanh:
Điểm khởi đầu của hành trình: GPT-1
OpenAI đã phát hành GPT-1 mô hình từ năm 2018. Phiên bản đầu tiên này là một khởi đầu đầy hứa hẹn, thể hiện khả năng của Transformers trong các tác vụ xử lý ngôn ngữ tự nhiên.
- Từ vựng: 40.000 từ
- Thông số: 117 triệu
- Lớp: 12 lớp biến áp
GPT-1Hạn chế đáng chú ý nhất của nó là khoảng chú ý ngắn, nghĩa là nó chỉ có thể xem xét 512 mã thông báo trước đó (từ hoặc phần của từ) khi tạo văn bản mới. Hạn chế này thường dẫn đến những đoạn văn dài không mạch lạc.
Sự phát triển vẫn tiếp tục: GPT-2
Nếu bạn muốn nâng cao hiểu biết của mình về bộ truyện này, hãy xem xét GPT-2 như một cột mốc quan trọng. Được giới thiệu vào năm 2019, mô hình này mang lại những cải tiến đáng kể trong việc tạo văn bản.
- Từ vựng: 50.000 từ
- thông số: 1.5 tỷ
- Lớp: 48 lớp biến áp
Đáng chú ý, GPT-2 đã được đào tạo trên một tập dữ liệu lớn hơn nhiều so với phiên bản tiền nhiệm, cung cấp kết quả đầu ra phong phú hơn. Hạn chế chính của nó, tương tự như GPT-1đó là khó khăn trong việc duy trì cấu trúc tường thuật dài hạn mạch lạc.
Một bước nhảy vọt lượng tử: GPT-3
Tiến xa hơn nữa, GPT-3 mô hình là một bước nhảy vọt đáng kể so với các phiên bản trước đó. OpenAI đã mở rộng mô hình này lên một mức độ chưa từng có.
- Từ vựng: 50.000 từ
- Thông số: 175 tỷ
- Lớp: 96 lớp biến áp
Mặc dù vẫn giữ nguyên kiến trúc như GPT-2GPT-3 mang lại một khả năng đáng ngạc nhiên: học tập trong vài lần. Điều này cho phép mô hình tạo ra kết quả đầu ra mong muốn chỉ với một vài ví dụ. Tuy nhiên, GPT-3 đã bị chỉ trích vì dễ tạo ra nội dung không phù hợp, do đó cần có các biện pháp kiểm duyệt chặt chẽ hơn.
Biên giới mới: GPT-4
Nếu bạn đang thắc mắc các mô hình GPT đã phát triển hơn nữa như thế nào, hãy xem xét GPT-4. Tính đến thời điểm viết bài, đây là phiên bản mới nhất được phát triển bởi OpenAI.
- Từ vựng: 50.000 từ
- Thông số: >175 tỷ (chưa rõ con số chính xác)
- Lớp: >96 lớp biến áp (không rõ số lượng chính xác)
GPT-4 nâng cao hơn nữa khả năng của phiên bản tiền nhiệm bằng cách cung cấp các phản hồi mang nhiều sắc thái và nhận biết ngữ cảnh hơn. Tuy nhiên, do độ phức tạp và kích thước của mô hình nên việc triển khai các ứng dụng thời gian thực là một thách thức đáng kể.
So sánh các mô hình: tiến bộ và hạn chế
Tóm lại, mỗi lần lặp lại GPT đều mang lại những tiến bộ về khả năng hiểu và tạo văn bản. Dưới đây là một cái nhìn nhanh về sự tiến hóa của họ:
- GPT-1 đã đặt nền móng, thể hiện tiềm năng của mô hình Transformer trong các tác vụ xử lý ngôn ngữ tự nhiên.
- GPT-2 đã cải thiện đáng kể chất lượng tạo văn bản nhưng vẫn gặp khó khăn với tính mạch lạc của câu chuyện lâu dài.
- GPT-3 đã có một bước nhảy vọt lớn với khả năng hiểu ngữ cảnh tốt hơn và thực hiện học tập trong vài lần, nhưng lại gặp phải các vấn đề đạo đức liên quan đến việc tạo nội dung.
- GPT-4 nâng cao hơn nữa khả năng của GPT-3cung cấp nhiều phản hồi đa sắc thái hơn nhưng lại đặt ra những thách thức khi triển khai do quy mô của nó.
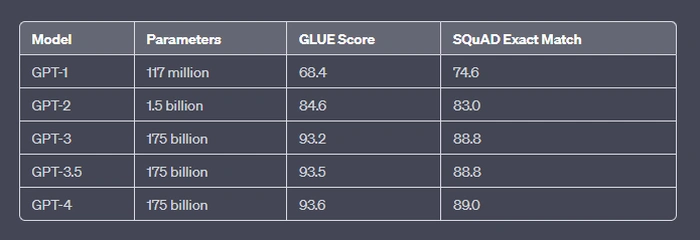
Tại sao nên trò chuyệnGPT 3.5 và ChatGPT-4 có cùng thông số
Trò chuyệnGPT 3.5 và ChatGPT-4 có cùng số lượng tham số, nhưng chúng là các mô hình khác nhau về kiến trúc và dữ liệu huấn luyện. Trò chuyệnGPT-4 là phiên bản cải tiến của ChatGPT 3.5và nó có một số ưu điểm như:
- Hiệu suất tốt hơn trong các nhiệm vụ NLP: Trò chuyệnGPT-4 đã được chứng minh là hoạt động tốt hơn ChatGPT 3.5 về một số nhiệm vụ NLP, chẳng hạn như trả lời câu hỏi, tóm tắt và dịch thuật.
- Cửa sổ ngữ cảnh lớn hơn: Trò chuyệnGPT-4 có thể giữ lại nhiều thông tin hơn từ các cuộc trò chuyện trước đó, điều này cho phép nó tạo ra các phản hồi toàn diện và nhiều thông tin hơn.
- Cải thiện khả năng xử lý các lời nhắc phức tạp: Trò chuyệnGPT-4 xử lý các lời nhắc phức tạp tốt hơn, chẳng hạn như những lời nhắc yêu cầu nhiều bước để hoàn thành.
- Quá trình đào tạo hiệu quả hơn: Trò chuyệnGPT-4 được đào tạo trên cơ sở hạ tầng phần cứng hiệu quả hơn, cho phép nó được đào tạo nhanh hơn và với chi phí thấp hơn.
Bất chấp những ưu điểm này, ChatGPT-4 không phải là một mô hình hoàn toàn mới. Nó vẫn dựa trên kiến trúc cơ bản giống như ChatGPT 3.5và nó có cùng số tham số.
Điểm GLUE và SQuAD là gì?
Sự tiến bộ nhanh chóng trong công nghệ xử lý ngôn ngữ tự nhiên (NLP) đòi hỏi một bộ tiêu chuẩn mạnh mẽ để đánh giá hiệu suất của các mô hình khác nhau. Đối với những người trong lĩnh vực này, hai số liệu quan trọng bạn sẽ thường gặp là GLUE và SQuAD. Hãy cùng tìm hiểu xem những điểm số này thể hiện điều gì và tại sao chúng lại quan trọng trong lĩnh vực NLP.
GLUE: Đánh giá hiểu biết ngôn ngữ chung
GLUE, viết tắt của Đánh giá hiểu ngôn ngữ chung, là một điểm chuẩn được sử dụng để đánh giá hiệu suất của các mô hình NLP trong một loạt nhiệm vụ. Những nhiệm vụ này, bao gồm phân tích tình cảm, trả lời câu hỏi và đánh giá độ tương tự của câu, cùng với những nhiệm vụ khác, được thiết kế để thách thức các mô hình ở các khía cạnh khác nhau của việc hiểu ngôn ngữ.
Mỗi nhiệm vụ trong điểm chuẩn GLUE là một bài toán phân loại nhị phân hoặc nhiều lớp. Các mô hình được tính điểm dựa trên độ chính xác của chúng (tỷ lệ phần trăm dự đoán đúng) cho mỗi nhiệm vụ. Sau đó, điểm số nhiệm vụ riêng lẻ này được tính trung bình để có được điểm GLUE cuối cùng. Điểm GLUE cao hơn biểu thị hiệu suất tổng thể tốt hơn trên các nhiệm vụ NLP đa dạng.
GLUE có tầm quan trọng to lớn vì nó cung cấp thước đo toàn diện về khả năng hiểu ngôn ngữ của mô hình. Nó đảm bảo rằng các mô hình không chỉ giỏi một nhiệm vụ cụ thể mà còn hiểu biết rộng hơn về các sắc thái ngôn ngữ.
SQuAD: Bộ dữ liệu trả lời câu hỏi của Stanford
SQuAD, hay Bộ dữ liệu trả lời câu hỏi của Stanford, là một điểm chuẩn khác được sử dụng để đánh giá hiệu suất đọc hiểu của máy. Trong SQuAD, mô hình NLP được cung cấp một đoạn văn bản và một câu hỏi về đoạn văn đó. Nhiệm vụ của người mẫu là đưa ra câu trả lời cho câu hỏi dựa trên nội dung của đoạn văn.
Các câu trả lời trong SQuAD được đánh giá dựa trên hai số liệu chính: Kết quả khớp chính xác (EM) và điểm F1. Điểm EM biểu thị tỷ lệ phần trăm câu trả lời của mô hình khớp chính xác với một trong những câu trả lời được chấp nhận. Điểm F1 xem xét cả độ chính xác (có bao nhiêu mục đã chọn có liên quan) và khả năng thu hồi (có bao nhiêu mục có liên quan được chọn), mang lại sự cân bằng giữa chúng.
SQuAD rất quan trọng trong lĩnh vực NLP vì nó đánh giá kỹ năng đọc hiểu của mô hình – khả năng hiểu một đoạn văn và trích xuất thông tin liên quan để trả lời các câu hỏi.
Tầm quan trọng của điểm chuẩn AI
Lý do tại sao điểm GLUE và SQuAD lại quan trọng đến vậy là vì chúng cung cấp những cách toàn diện để đo lường hiệu suất của các mô hình NLP qua các nhiệm vụ khác nhau. Chúng giúp so sánh các mô hình khác nhau với nhau, tạo điều kiện so sánh và hiểu rõ điểm mạnh và điểm yếu của từng mô hình.
Tóm lại, nếu bạn đang hướng tới việc đánh giá toàn diện về mô hình NLP, thì việc xem xét cả điểm GLUE và SQuAD là điều hết sức quan trọng. Họ đưa ra một bài kiểm tra nghiêm ngặt và linh hoạt về khả năng hiểu và đọc hiểu ngôn ngữ của mô hình, điều này rất quan trọng đối với hiệu suất của mô hình trong các ứng dụng trong thế giới thực.
Dưới đây là một số điểm khác biệt chính giữa GLUE và SQuAD:
- Số lượng nhiệm vụ: GLUE là tập hợp chín nhiệm vụ NLP khác nhau, trong khi SQuAD là một nhiệm vụ duy nhất.
- Kích thước tập dữ liệu: Tập dữ liệu GLUE nhỏ hơn tập dữ liệu SQuAD.
- Độ khó của nhiệm vụ: Nhiệm vụ GLUE thường được coi là khó hơn nhiệm vụ SQuAD.
- Nhìn chung, GLUE là điểm chuẩn toàn diện hơn SQuAD nhưng cũng khó đạt được điểm cao trên GLUE hơn. SQuAD là một điểm chuẩn đơn giản hơn nhưng vẫn là thước đo tốt về khả năng trả lời câu hỏi của mô hình.
Thông tin thêm về điểm chuẩn của các mô hình GPT hãy truy cập cả KEO DÁN Và BIỆT ĐỘI các trang web cho rõ ràng.
Tuyên bố từ chối trách nhiệm: Một số bài viết của chúng tôi bao gồm các liên kết liên kết. Nếu bạn mua thứ gì đó thông qua một trong những liên kết này, APS Blog có thể kiếm được hoa hồng liên kết. Tìm hiểu về Chính sách tiết lộ của chúng tôi.
