

1 Vào tháng 9 năm 2020, NVIDIA đã tiết lộ dòng GPU chơi game mới của mình: dòng RTX 3000, dựa trên kiến trúc Ampere. Chúng tôi sẽ đề cập đến những tính năng mới, bao gồm phần mềm hỗ trợ AI và tất cả các chi tiết khiến thế hệ này thực sự tuyệt vời.
Làm quen với GPU dòng RTX 3000
Thông báo chính của NVIDIA là GPU mới sáng bóng, tất cả đều được xây dựng bằng quy trình sản xuất tùy chỉnh 8 nm và tất cả đều cung cấp khả năng tăng tốc đáng kể trong cả quá trình tạo điểm ảnh và dò tia.
Ở cấp thấp nhất của dòng sản phẩm là RTX 3070 được bán lẻ với giá 499 đô la. Nó hơi đắt đối với thẻ rẻ nhất được NVIDIA tiết lộ trong thông báo đầu tiên, nhưng đó là một sự ăn cắp tuyệt đối khi bạn biết rằng nó đánh bại RTX 2080 Ti hiện có, thẻ hàng đầu trong dòng thường được bán với giá hơn 1.400 đô la . Tuy nhiên, sau thông báo của NVIDIA, giá bán của bên thứ ba đã giảm xuống, với nhiều người bán một cách hoảng loạn trên eBay với giá dưới 600 đô la.
Không có điểm chuẩn vững chắc tại thời điểm công bố, vì vậy không rõ liệu thẻ này có thực sự “tốt hơn” một cách khách quan so với 2080 Ti hay NVIDIA đang vặn vẹo hoạt động tiếp thị một chút. Các điểm chuẩn ở độ phân giải 4K và có thể đã bật RTX, điều này có thể tạo ra sự khác biệt lớn hơn so với các trò chơi được quét điểm thuần túy, vì dòng 3000 dựa trên Ampere sẽ hoạt động theo dõi tia tốt hơn gấp đôi so với Turing. Nhưng vì tính năng dò tia giờ đây không ảnh hưởng quá nhiều đến hiệu suất và được hỗ trợ trên bảng điều khiển thế hệ mới nhất, nên điểm hấp dẫn chính là nó chạy nhanh như chiếc flagship thế hệ trước với mức giá chỉ bằng một phần ba.
Cũng không rõ liệu giá có duy trì ở mức này hay không. Các thiết kế của bên thứ ba thường tăng thêm ít nhất 50 đô la vào giá và do nhu cầu sẽ cao đến mức nào, sẽ không ngạc nhiên khi thấy nó được bán lẻ với giá 600 đô la vào tháng 10 năm 2020.
Ngay trên đó là RTX 3080 với giá 699 USD, nhanh gấp đôi so với RTX 2080 và nhanh hơn khoảng 25-30% so với 3080.
Sau đó, ở trên cùng, chiếc flagship mới là RTX 3090, rất lớn. NVIDIA nhận thức được điều này và gọi nó là “BFGPU”, mà công ty cho biết là viết tắt của “Big Ferocious GPU”.

NVIDIA đã không cung cấp bất kỳ số liệu hiệu suất trực tiếp nào, nhưng công ty đã cho thấy nó chạy các trò chơi 8K ở 60 FPS, điều này thực sự ấn tượng. Đúng là NVIDIA gần như chắc chắn sẽ sử dụng DLSS để đạt được mục tiêu này, nhưng trò chơi 8K là trò chơi 8K.
Tất nhiên, 3060 và các biến thể thẻ định hướng ngân sách khác cuối cùng sẽ xuất hiện, nhưng chúng có xu hướng đến sau.
Để thực sự hạ nhiệt mọi thứ, NVIDIA cần một thiết kế mát mẻ hơn. 3080 được đánh giá ở mức 320 watt, khá cao, vì vậy NVIDIA đã chọn thiết kế quạt kép, nhưng thay vì đặt hai quạt vwinf ở phía dưới, NVIDIA đã đặt quạt ở đầu trên cùng, nơi thường đặt tấm ốp lưng. Quạt hướng không khí lên phía trên bộ làm mát CPU và mặt trên của khung máy.

Đánh giá mức độ hiệu suất có thể bị ảnh hưởng bởi luồng không khí kém trong trường hợp, điều đó có ý nghĩa. Tuy nhiên, PCB rất chặt chẽ vì điều này, có khả năng ảnh hưởng đến giá bán của bên thứ ba.
DLSS: lợi thế phần mềm
Truy tìm tia không phải là lợi thế duy nhất của những thẻ mới này. Thực sự, đó là một chút rắc rối – sê-ri RTX 2000 và sê-ri 3000 không tốt hơn nhiều trong việc thực hiện dò tia thực tế so với các thẻ thế hệ cũ. Truy tìm tia của các cảnh đầy đủ trong phần mềm 3D như Blender thường mất vài giây hoặc thậm chí vài phút cho mỗi khung hình, do đó, brute force nó trong vòng dưới 10 mili giây là điều không cần bàn cãi.
Tất nhiên, có phần cứng chuyên dụng để thực hiện các tính toán bán kính được gọi là lõi RT, nhưng phần lớn NVIDIA đã chọn một cách tiếp cận khác. NVIDIA đã cải thiện các thuật toán khử nhiễu cho phép GPU hiển thị một đường chuyền rất rẻ trông thật tệ và bằng cách nào đó – thông qua sự kỳ diệu của AI – biến nó thành thứ mà game thủ muốn xem. Kết hợp với các kỹ thuật truyền thống dựa trên quá trình rasterization, nó mang lại trải nghiệm thú vị được tăng cường bởi các hiệu ứng dò tia.

Tuy nhiên, để thực hiện điều này một cách nhanh chóng, NVIDIA đã bổ sung các lõi xử lý dành riêng cho AI được gọi là lõi Tensor. Họ xử lý tất cả các phép toán cần thiết để chạy các mô hình máy học và họ thực hiện rất nhanh chóng. Nhìn chung, chúng đều là yếu tố thay đổi cuộc chơi cho AI trong không gian máy chủ đám mây vì AI được nhiều công ty sử dụng rộng rãi.
Bên cạnh việc khử nhiễu, công dụng chính của lõi Tensor dành cho game thủ là DLSS hoặc siêu lấy mẫu học sâu. Nó lấy một khung chất lượng thấp và chia tỷ lệ thành chất lượng gốc đầy đủ. Về cơ bản, điều này có nghĩa là bạn có thể chơi trò chơi ở tốc độ khung hình 1080p trong khi xem hình ảnh 4K.
Điều này cũng giúp cải thiện hiệu suất dò tia – Điểm chuẩn PCMag cho thấy RTX 2080 Super Running Control ở chất lượng cực cao, với tất cả các cài đặt dò tia được đặt ở mức tối đa. Ở 4K, nó chỉ gặp khó khăn với 19 FPS, nhưng khi bật DLSS, nó đạt được 54 FPS tốt hơn nhiều. DLSS là hiệu năng miễn phí dành cho NVIDIA, được thực hiện nhờ các lõi Tensor trong Turing và Ampere. Bất kỳ trò chơi nào hỗ trợ điều này và bị giới hạn ở GPU chỉ có thể nhận thấy sự gia tăng đáng kể từ chính phần mềm.
DLSS không phải là mới và đã được công bố là một tính năng khi dòng RTX 2000 được phát hành hai năm trước. Vào thời điểm đó, rất ít trò chơi hỗ trợ nó vì nó yêu cầu NVIDIA đào tạo và điều chỉnh mô hình máy học cho từng trò chơi.
Tuy nhiên, lúc đó NVIDIA đã viết lại hoàn toàn, gọi phiên bản mới là DLSS 2.0. Đó là một API có mục đích chung, nghĩa là bất kỳ nhà phát triển nào cũng có thể triển khai nó và nó đã có sẵn trong hầu hết các bản phát hành chính. Thay vì làm việc trên một khung hình, nó tìm nạp dữ liệu vectơ từ khung hình trước đó khi đang di chuyển, giống như TAA. Kết quả sắc nét hơn nhiều so với DLSS 1.0và trong một số trường hợp, nó thực sự trông đẹp hơn và sắc nét hơn cả độ phân giải gốc, vì vậy không có lý do gì để không kích hoạt nó.
Có một nhược điểm – khi chuyển cảnh hoàn toàn, như trong đoạn phim cắt cảnh, DLSS 2.0 cần hiển thị khung hình đầu tiên ở chất lượng 50% trong khi chờ dữ liệu vectơ chuyển động. Điều này có thể làm giảm chất lượng một chút trong vài mili giây. Nhưng 99% mọi thứ bạn xem sẽ hiển thị chính xác và hầu hết mọi người không nhận thấy điều này trong thực tế.
Kiến trúc Ampe: được xây dựng cho AI
Ampe nhanh. Cực kỳ nhanh, đặc biệt là với tính toán AI. Cốt lõi của RT là 1Nhanh hơn .7 lần so với Turing và lõi Tensor mới là 2Nhanh hơn .7 lần so với Turing. Sự kết hợp của hai yếu tố này là một bước nhảy vọt mang tính thế hệ thực sự trong hiệu suất dò tia.

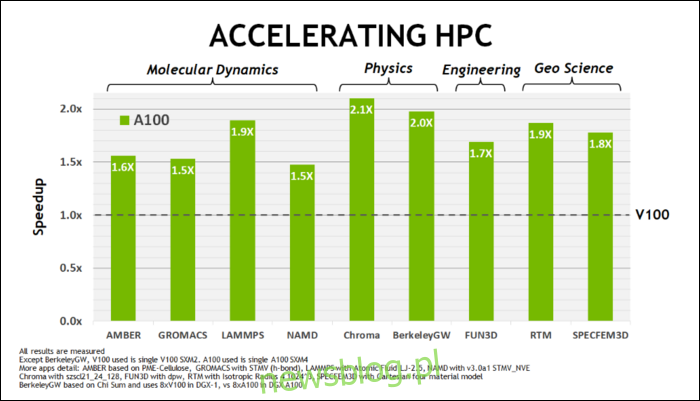
Đầu tháng 5 năm nay, NVIDIA đã phát hành GPU Ampere A100, GPU dành cho trung tâm dữ liệu được thiết kế để hỗ trợ trí tuệ nhân tạo. Với nó, họ trình bày chi tiết những gì làm cho Ampere nhanh hơn rất nhiều. Đối với các trung tâm dữ liệu và khối lượng công việc tính toán hiệu năng cao, Ampere thường xấp xỉ 1,7 nhanh hơn Turing nhiều lần. Trong trường hợp đào tạo, AI lên đến 6 nhanh hơn nhiều lần.
Đối với Ampere, NVIDIA sử dụng định dạng số mới được thiết kế để thay thế tiêu chuẩn ngành “32 dấu phẩy động” hoặc FP32 trong một số khối lượng công việc. Về cơ bản, mọi số được máy tính xử lý chiếm một số bit được xác định trước trong bộ nhớ, cho dù đó có phải là số hay không. 8 bit, 16 bit, 32, 64 hoặc thậm chí nhiều hơn. Các số lớn hơn sẽ khó xử lý hơn, vì vậy nếu bạn có thể sử dụng kích thước nhỏ hơn, bạn sẽ ít phải bẻ khóa hơn.
FP32 lưu trữ số thập phân 32 bit và sử dụng 8 bit cho phạm vi của số (số đó có thể lớn hay nhỏ) và 23 bit cho độ chính xác. NVIDIA cho biết 23 bit chính xác này không hoàn toàn cần thiết đối với nhiều khối lượng công việc AI và bạn có thể nhận được kết quả tương tự cũng như hiệu suất tốt hơn nhiều chỉ với 10 bit trong số đó. Việc giảm kích thước xuống chỉ còn 19 bit thay vì 32 bit sẽ tạo ra sự khác biệt lớn trong nhiều phép tính.
Định dạng mới này được gọi là Tensor Float 32 và các lõi Tensor trong A100 được tối ưu hóa để xử lý định dạng có kích thước lẻ. Đó là, ngoài việc thu nhỏ khuôn và tăng số lượng lõi, chúng còn trở nên khổng lồ 6-tăng tốc gấp trong đào tạo AI.

Ngoài định dạng số mới, Ampere đang chứng kiến hiệu suất tăng đáng kể trong các tính toán cụ thể như FP32 và FP64. Chúng không trực tiếp chuyển thành tốc độ khung hình cao hơn cho người bình thường, nhưng chúng là một phần giúp nó nhanh hơn gần ba lần trong các hoạt động của Tensor.

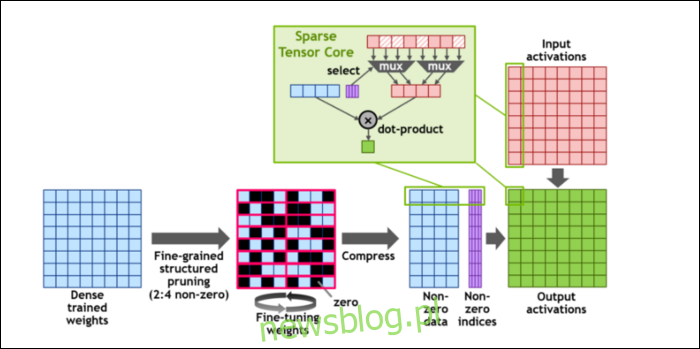
Sau đó, để tăng tốc độ tính toán hơn nữa, họ đã đưa ra khái niệm cấu trúc thưa hạt mịn, đây là một từ rất hoa mỹ cho một khái niệm khá đơn giản. Mạng lưới thần kinh hoạt động với danh sách lớn các số, được gọi là trọng số, ảnh hưởng đến điểm số cuối cùng. Càng nhiều số để bẻ khóa, nó sẽ càng chậm.
Tuy nhiên, không phải tất cả những con số này đều thực sự hữu ích. Một số trong số chúng thực sự là vô giá trị và về cơ bản có thể bị vứt đi, dẫn đến tốc độ tăng tốc lớn khi bạn có thể ép nhiều số hơn cùng một lúc. Về cơ bản, thưa thớt nén các con số, đòi hỏi ít nỗ lực hơn để thực hiện các phép tính. “Sparse Tensor Core” mới được xây dựng để chạy trên dữ liệu nén.
Bất chấp những thay đổi, NVIDIA cho biết điều này sẽ không ảnh hưởng đến độ chính xác của các mô hình được đào tạo theo bất kỳ cách nào.
Đối với các phép tính INT8 thưa thớt, một trong những định dạng số nhỏ nhất, hiệu suất cao nhất của một GPU A100 đã hết 1.25 PetaFLOPs, đây là một con số cao đáng kinh ngạc. Tất nhiên, điều này chỉ xảy ra khi tính toán một loại số cụ thể, nhưng dù sao nó cũng rất ấn tượng.
