
Trang web này có thể có được hoa hồng liên kết từ các liên kết trên trang này. Điều khoản sử dụng 
Trong những năm gần đây, Intel đã thảo luận về các máy chủ Cascade Lake với DL Boost (còn được gọi là VNNI, Hướng dẫn sử dụng Vector thần kinh). Khả năng mới này là một phần của AVX-512 và nhằm tăng tốc hiệu suất CPU trong các ứng dụng AI. Trong lịch sử, nhiều ứng dụng AI thích GPU hơn CPU. Kiến trúc GPU: Bộ xử lý song song quy mô lớn với hiệu năng đơn luồng thấp, phù hợp với bộ xử lý đồ họa hơn CPU. CPU cung cấp nhiều tài nguyên thực thi hơn trên mỗi luồng, nhưng ngay cả CPU đa lõi cũng bị lấn át bởi sự song song có sẵn trong các lõi GPU cao cấp.
Anandtech đã so sánh hiệu năng của Cascade Lake, Epyc 7601 (sẽ sớm bị CPU AMD vượt qua 7 cách Rome, nhưng vẫn là máy chủ chính của AMD ngày nay) và Titan RTX. Bài viết của Johan De Gelas rất hay, thảo luận về nhiều loại mạng thần kinh khác nhau ngoài CNN (Mạng thần kinh chuyển đổi) thường được so sánh và các phần quan trọng trong chiến lược của Intel cạnh tranh với Nvidia trong khối lượng công việc trong đó GPU không mạnh hoặc vẫn không thể đáp ứng nhu cầu thị trường phát sinh do dung lượng bộ nhớ hạn chế (GPU vẫn không thể phù hợp với CPU ở đây), sử dụng các mô hình AI "nhẹ" không mất thời gian đào tạo kéo dài hoặc mô hình trí tuệ nhân tạo phụ thuộc vào mô hình thống kê của các mạng phi thần kinh.
Tăng doanh thu trung tâm dữ liệu là một thành phần quan trọng trong nỗ lực chung của Intel đối với AI và học máy. Nvidia, trong khi đó, muốn bảo vệ một thị trường hiện đang cạnh tranh gần như một mình. Chiến lược AI của Intel rất rộng và trải rộng trên nhiều sản phẩm, từ Movidius và Nervana đến DL Boost trên Xeon, cho đến dòng GPU Xe tiếp theo. Nvidia cố gắng chỉ ra rằng GPU có thể được sử dụng để xử lý các tính toán AI trên phạm vi khối lượng công việc rộng hơn. Intel đang phát triển các khả năng AI mới trong các sản phẩm hiện có, tung ra phần cứng mới dự kiến sẽ có tác động đến thị trường và đang cố gắng xây dựng GPU nghiêm trọng đầu tiên của mình để thách thức công việc của AMD và Nvidia trên mọi không gian của người tiêu dùng. .
Điều mà các điểm chuẩn của Anandtech thể hiện, cùng nhau, là khoảng cách giữa Intel và Nvidia vẫn còn rộng, ngay cả với DL Boost. Đồ họa này là từ thử nghiệm Mạng tái phát thường xuyên bằng cách sử dụng mạng "Bộ nhớ ngắn hạn (LSTM) làm mạng thần kinh. Một loại RNN, LSTM" chọn lọc "các mẫu trong một khoảng thời gian nhất định." Anandtech cũng sử dụng ba cấu hình khác nhau để kiểm tra nó: Tensorflow với điều kiện không tương thích, với Tensorflow được Intel tối ưu hóa với PyPi và một phiên bản Tensorflow được tối ưu hóa từ các nguồn sử dụng Bazel, sử dụng phiên bản mới nhất của Tensorflow.

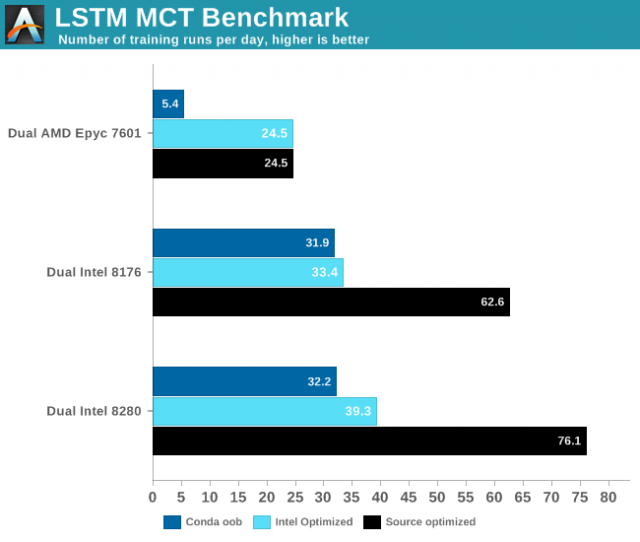
Hình ảnh của Anandtech
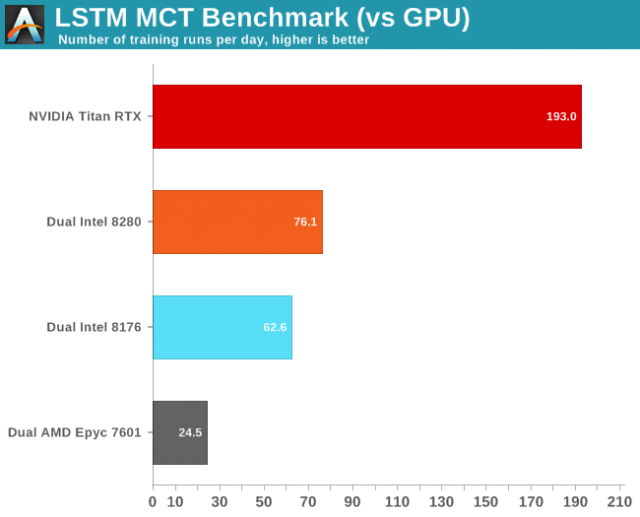
Hình ảnh của Anandtech
Cặp ảnh này chụp tỷ lệ tương đối giữa CPU và cả so sánh của nó với Titan RTX. Hết hiệu năng Các hộp khá tệ trên AMD, mặc dù chúng được cải tiến với mã được tối ưu hóa. Hiệu suất của Intel tăng vọt khi phiên bản tối ưu hóa ban đầu được thử nghiệm, nhưng ngay cả phiên bản tối ưu hóa ban đầu cũng không hoàn toàn phù hợp với hiệu suất của Titan RTX. De Gelas lưu ý: "Thứ hai, chúng tôi khá ngạc nhiên khi Titan RTX của chúng tôi kém hơn 3 nhanh hơn nhiều lần so với thiết lập Xeon kép của chúng tôi ", cho bạn biết cách so sánh này hoạt động trong một bài viết dài hơn.
DL Boost không đủ để thu hẹp khoảng cách giữa Intel và Nvidia, nhưng công bằng mà nói, có lẽ không nên như vậy. Mục tiêu của Intel ở đây là cải thiện hiệu suất AI đủ trong Xeon để làm cho khối lượng công việc này có ý nghĩa trên một máy chủ sẽ được sử dụng chủ yếu cho những thứ khác hoặc bằng cách xây dựng các mô hình AI không phù hợp với các hạn chế GPU hiện đại. Mục tiêu dài hạn của công ty là cạnh tranh trong thị trường AI với nhiều thiết bị khác nhau, không chỉ Xeon. Với Xe chưa sẵn sàng, cạnh tranh trong không gian HPC bây giờ có nghĩa là cạnh tranh với Xeon.
Đối với những người bạn thắc mắc về AMD, AMD không thực sự nói về việc chạy khối lượng công việc AI trên CPU Epyc, mà thay vào đó tập trung vào sáng kiến của RocM để chạy mã CUDA trong OpenCL. AMD không nói nhiều về khía cạnh kinh doanh này, nhưng Nvidia thống trị thị trường ứng dụng GPU AI và HPC. Cả AMD và Intel đều muốn có không gian. Ngay bây giờ, cả hai dường như có một thời gian khó khăn để yêu cầu một.
Bây giờ đọc:
