
Trang web này có thể có được hoa hồng liên kết từ các liên kết trên trang này. Điều khoản sử dụng. 
Giờ đây, chỉ với mỗi thiết bị và thiết bị di động mà họ có thể đã áp dụng hoặc ít nhất là đã thử nghiệm điều khiển bằng giọng nói, cuộc trò chuyện AI đang nhanh chóng trở thành một biên giới mới. Thay vì xử lý một yêu cầu duy nhất và đưa ra phản hồi hoặc hành động, Hội thoại AI nhằm mục đích cung cấp một sistema Tương tác trong thời gian thực có thể đạt được nhiều câu hỏi, câu trả lời và bình luận. Mặc dù các thành phần cốt lõi của các cuộc hội thoại AI, như BERT và RoBERTa cho mô hình hóa ngôn ngữ, tương tự như các thành phần để nhận dạng giọng nói đơn, các khái niệm này được bổ sung bởi các yêu cầu hiệu suất bổ sung cho đào tạo, suy luận và kích thước của các mô hình. Hôm nay, Nvidia đã phát hành ba công nghệ nguồn mở được thiết kế để giải quyết vấn đề.
Đào tạo BERT nhanh hơn
 Mặc dù trong nhiều trường hợp, có thể sử dụng các mô hình ngôn ngữ được đào tạo trước cho riêng các tác vụ mới, để có hiệu suất tối ưu trong các bối cảnh nhất định, điều cần thiết là phải đào tạo lại. Nvidia đã chỉ ra rằng bây giờ bạn có thể đào tạo BERT (Mô hình ngôn ngữ tham khảo của Google) trong chưa đầy một giờ trong DGX SuperPOD, bao gồm 1.472 GPU Tesla V100-SXM3-32GB, 92 máy chủ DGX-2H và 10 Mellanox Infiniband mỗi nút. Không, tôi thậm chí không muốn ước tính giá cho thuê hàng giờ cho một trong số họ. Nhưng bởi vì một mô hình như thế này thường mất nhiều ngày để đào tạo ngay cả trên các cụm GPU cao cấp, điều này chắc chắn sẽ giúp thương mại hóa các công ty có thể chi trả chi phí.
Mặc dù trong nhiều trường hợp, có thể sử dụng các mô hình ngôn ngữ được đào tạo trước cho riêng các tác vụ mới, để có hiệu suất tối ưu trong các bối cảnh nhất định, điều cần thiết là phải đào tạo lại. Nvidia đã chỉ ra rằng bây giờ bạn có thể đào tạo BERT (Mô hình ngôn ngữ tham khảo của Google) trong chưa đầy một giờ trong DGX SuperPOD, bao gồm 1.472 GPU Tesla V100-SXM3-32GB, 92 máy chủ DGX-2H và 10 Mellanox Infiniband mỗi nút. Không, tôi thậm chí không muốn ước tính giá cho thuê hàng giờ cho một trong số họ. Nhưng bởi vì một mô hình như thế này thường mất nhiều ngày để đào tạo ngay cả trên các cụm GPU cao cấp, điều này chắc chắn sẽ giúp thương mại hóa các công ty có thể chi trả chi phí.
Suy luận mô hình ngôn ngữ nhanh hơn
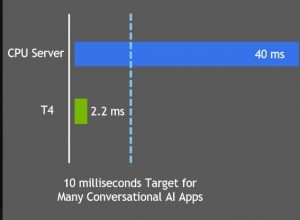
Đối với cuộc trò chuyện tự nhiên, điểm chuẩn của ngành là thời gian phản hồi 10 ms. Hiểu truy vấn và cung cấp câu trả lời được đề xuất chỉ là một phần của quy trình, do đó, chỉ mất chưa đến 10 ms. Khi tối ưu hóa BERT bằng cách sử dụng TensorRT 5.1, Nvidia đã kết luận nó trong 2.2ms trên Nvidia T4. Điều tốt là T4 thực sự nằm trong tầm tay của hầu hết các dự án nghiêm túc. Tôi sử dụng nó trong Google Compute Cloud cho tôi sistema thế hệ văn bản. Máy chủ ảo 4-vCPU với T4 cho thuê chỉ hơn $ 1 / giờ khi tôi làm dự án.
Hỗ trợ cho các mô hình lớn hơn
 Một trong những điểm nổi bật của mô thần kinh Achilles là yêu cầu tất cả các thông số mô hình (bao gồm một số lượng lớn trọng lượng) phải có trong bộ nhớ cùng một lúc. Điều đó giới hạn sự phức tạp của mô hình có thể được đào tạo trên GPU bởi kích thước RAM của nó. Trong trường hợp của tôi, ví dụ, máy tính để bàn của tôi là Nvidia GTX 1080
Một trong những điểm nổi bật của mô thần kinh Achilles là yêu cầu tất cả các thông số mô hình (bao gồm một số lượng lớn trọng lượng) phải có trong bộ nhớ cùng một lúc. Điều đó giới hạn sự phức tạp của mô hình có thể được đào tạo trên GPU bởi kích thước RAM của nó. Trong trường hợp của tôi, ví dụ, máy tính để bàn của tôi là Nvidia GTX 1080 Bạn chỉ có thể đào tạo mô hình phù hợp với 8GB của bạn. Tôi có thể đào tạo một mô hình lớn hơn trên CPU của mình, có nhiều RAM hơn, nhưng mất nhiều thời gian hơn. Mô hình ngôn ngữ GPT2 hoàn chỉnh có 1,5 một tỷ tham số chẳng hạn và phiên bản mở rộng có 8,3 tỷ
Bạn chỉ có thể đào tạo mô hình phù hợp với 8GB của bạn. Tôi có thể đào tạo một mô hình lớn hơn trên CPU của mình, có nhiều RAM hơn, nhưng mất nhiều thời gian hơn. Mô hình ngôn ngữ GPT2 hoàn chỉnh có 1,5 một tỷ tham số chẳng hạn và phiên bản mở rộng có 8,3 tỷ

Tuy nhiên, Nvidia đã nghĩ ra cách cho phép nhiều GPU hoạt động song song với các ngôn ngữ mô hình hóa. Giống như các thông báo khác ngày hôm nay, họ đã mở mã nguồn để thực hiện điều này. Tôi muốn biết liệu kỹ thuật này dành riêng cho các mô hình ngôn ngữ hay liệu nó có thể được áp dụng để cho phép đào tạo nhiều GPU cho các loại mạng thần kinh khác hay không.
Cùng với sự phát triển và khởi chạy mã này trên GitHub, Nvidia tuyên bố rằng họ sẽ hợp tác với Microsoft để cải thiện kết quả tìm kiếm Bing, cũng như Clinc trên các tác nhân giọng nói, AI Passage trên chatbot và RecordSure trên các phân tích hội thoại.
Bây giờ đọc:
