
Ma trận nhầm lẫn là một công cụ để đánh giá hiệu suất của một loại thuật toán học máy được giám sát.
một ma trận nhầm lẫn là gì?
Con người chúng ta nhìn mọi thứ khác đi – kể cả sự thật và dối trá. Những gì có vẻ giống như một dòng 10 cm đối với tôi có vẻ như đối với bạn 9 cm. Nhưng giá trị thực tế có thể 9, 10 hoặc cái gì khác. Chúng tôi đoán rằng đây là giá trị dự đoán!
Bộ não con người suy nghĩ như thế nào
Giống như bộ não của chúng ta sử dụng logic riêng để đưa ra dự đoán, máy móc sử dụng các thuật toán khác nhau (được gọi là thuật toán học máy) để nhận giá trị dự đoán của một câu hỏi. Một lần nữa, các giá trị này có thể giống hoặc khác với giá trị thực tế.
Trong một thế giới cạnh tranh, chúng ta muốn biết những dự đoán của mình là đúng hay sai để hiểu được kết quả của mình. Theo cách tương tự, chúng ta có thể xác định hiệu suất của thuật toán học máy dựa trên số lượng dự đoán được đưa ra chính xác.
Vậy thuật toán học máy là gì?
Máy cố gắng đưa ra câu trả lời cụ thể cho một vấn đề bằng cách áp dụng một logic hoặc tập hợp các hướng dẫn nhất định, được gọi là thuật toán máy học. Các thuật toán học máy có ba loại – được giám sát, không được giám sát hoặc tăng cường.
Các loại thuật toán học máy
Các loại thuật toán đơn giản nhất được giám sát, trong đó chúng ta đã biết câu trả lời và huấn luyện máy móc tìm ra câu trả lời đó bằng cách huấn luyện thuật toán với rất nhiều dữ liệu – giống như một đứa trẻ sẽ phân biệt những người thuộc các nhóm tuổi khác nhau bằng cách nhìn vào các đặc điểm của họ. và hơn nữa.
Các thuật toán ML được giám sát có hai loại – phân loại và hồi quy.
Các thuật toán phân loại phân loại hoặc sắp xếp dữ liệu dựa trên một số bộ tiêu chí. Ví dụ: nếu bạn muốn thuật toán của mình phân nhóm khách hàng dựa trên sở thích ăn uống của họ – những người thích pizza và những người không thích pizza, thì bạn sẽ sử dụng một thuật toán phân loại như Decision Tree, Random Forest, Naive Bayes hoặc SVM (hỗ trợ Máy vectơ ).
Thuật toán nào trong số này sẽ thực hiện công việc tốt nhất? Tại sao bạn chọn một thuật toán hơn thuật toán kia?
Nhập ma trận nhầm lẫn….
Ma trận nhầm lẫn là một ma trận hoặc bảng chứa thông tin về độ chính xác của thuật toán phân loại trong việc phân loại tập dữ liệu. Chà, cái tên không nhằm mục đích gây nhầm lẫn cho mọi người, nhưng có quá nhiều dự đoán sai có thể là do thuật toán đã sai 😉!
Do đó, ma trận nhầm lẫn là một phương pháp để đánh giá hiệu suất của thuật toán phân loại.
Làm sao?
Giả sử bạn đã áp dụng các thuật toán khác nhau cho vấn đề nhị phân đã đề cập trước đây của chúng tôi: phân loại (tách biệt) mọi người dựa trên việc họ có thích pizza hay không. Để đánh giá thuật toán có giá trị gần nhất với câu trả lời đúng, bạn sẽ sử dụng ma trận nhầm lẫn. Đối với bài toán phân loại nhị phân (like/dislike, true/false, 1/ /0) ma trận nhầm lẫn đưa ra bốn giá trị lưới, cụ thể là:
- Tích cực thực sự (TP)
- Tiêu cực thực sự (TN)
- Dương tính giả (FP)
- Âm tính giả (FN)
Bốn lưới trong ma trận nhầm lẫn là gì?
Bốn giá trị được xác định bởi ma trận nhầm lẫn tạo thành các lưới của ma trận.
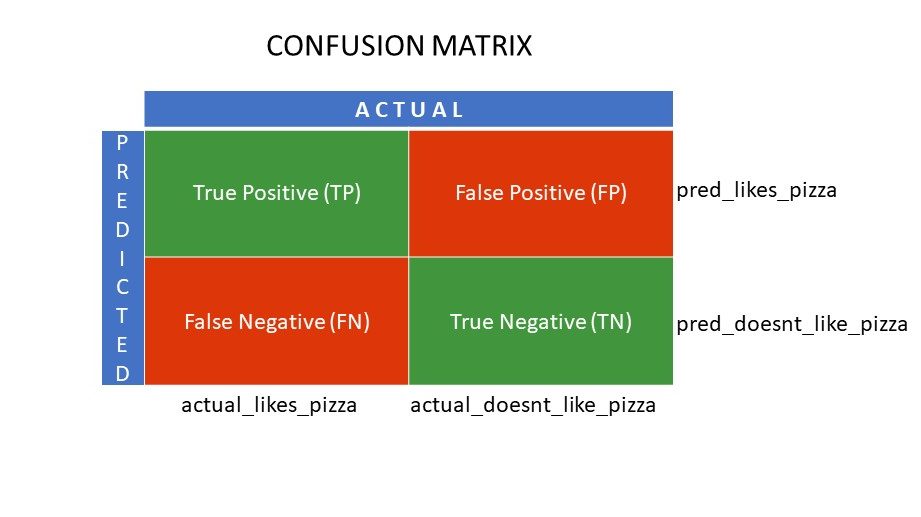 Lưới ma trận lỗi
Lưới ma trận lỗi
True positive (TP) và True Negative (TN) là các giá trị được dự đoán chính xác bởi thuật toán phân loại,
- TP đại diện cho những người thích pizza và mô hình đã phân loại chính xác họ,
- TN đại diện cho những người không thích pizza và mô hình đã phân loại chính xác họ,
Giá trị dương tính giả (FP) và âm tính giả (FN) là các giá trị được bộ phân loại dự đoán không chính xác,
- FP đại diện cho những người không thích pizza (tiêu cực) nhưng bộ phân loại đã dự đoán rằng họ thích pizza (dương tính giả). FP còn được gọi là lỗi Loại I.
- FN đại diện cho những người thích pizza (tích cực) nhưng bộ phân loại dự đoán là không (tiêu cực sai). FN còn được gọi là lỗi Loại II.
Để hiểu rõ hơn về khái niệm này, chúng ta hãy lấy một tình huống thực tế.
Giả sử bạn có tập dữ liệu gồm 400 người đã được xét nghiệm Covid. Bây giờ bạn có kết quả của các thuật toán khác nhau đã xác định số lượng người dương tính và âm tính với Covid.
Đây là hai ma trận nhầm lẫn để so sánh:
Nhìn vào cả hai, bạn có thể muốn nói rằng thuật toán đầu tiên chính xác hơn. Tuy nhiên, để có được một kết quả cụ thể, chúng tôi cần một số số liệu có thể đo lường độ chính xác, độ chính xác và nhiều giá trị khác chứng minh thuật toán nào tốt hơn.
Số liệu sử dụng ma trận lỗi và ý nghĩa của chúng
Các chỉ số chính giúp chúng tôi quyết định xem bộ phân loại có đưa ra dự đoán đúng hay không là:
#1. thu hồi/độ nhạy
Thu hồi hoặc Độ nhạy hoặc Tỷ lệ dương tính thực (TPR) hoặc Xác suất phát hiện là tỷ lệ của các dự đoán dương tính chính xác (TP) trên tổng số dương tính (tức là TP và FN).
R = TP/(TP + FN)
Thu hồi là thước đo số lượng tích cực hợp lệ được trả về từ số lượng tích cực hợp lệ có thể thu được. Giá trị Nhớ lại cao hơn có nghĩa là ít phủ định sai hơn, điều này tốt cho thuật toán. Sử dụng Nhắc nhở khi điều quan trọng là phải biết về kết quả âm tính giả. Ví dụ, nếu một người có nhiều tắc nghẽn trong tim và mô hình cho thấy họ hoàn toàn ổn, điều đó có thể gây tử vong.
#2. Độ chính xác
Độ chính xác là thước đo các kết quả dương tính chính xác trong số tất cả các kết quả dương tính được dự đoán, bao gồm cả kết quả dương tính đúng và sai.
Pr = TP/(TP + FP)
Độ chính xác là rất quan trọng khi dương tính giả là quá quan trọng để bỏ qua. Ví dụ, nếu một người không mắc bệnh tiểu đường, nhưng mô hình cho thấy nó và bác sĩ kê toa một số loại thuốc. Điều này có thể dẫn đến tác dụng phụ nghiêm trọng.
#3. độ đặc hiệu
Độ đặc hiệu hoặc Tỷ lệ âm tính thực sự (TNR) là kết quả âm tính bình thường trong số tất cả các kết quả có thể âm tính.
S = TN/(TN + FP)
Đây là thước đo mức độ bộ phân loại của bạn xác định các giá trị âm.
#4. Độ chính xác
Độ chính xác là số dự đoán đúng trên tổng số dự đoán. Vì vậy, nếu bạn tìm thấy đúng 20 giá trị dương và 10 giá trị âm từ một mẫu 50, thì độ chính xác của mô hình của bạn sẽ là 30/50.
Độ chính xác A = (TP + TN)/(TP + TN + FP + FN)
#5. Truyền đi
Tỷ lệ mắc bệnh là thước đo số lượng kết quả tích cực thu được từ tất cả các kết quả.
P = (TP + FN)/(TP + TN + FP + FN)
#6. điểm F
Đôi khi rất khó để so sánh hai bộ phân loại (mô hình) chỉ sử dụng Chính xác và Thu hồi, chúng chỉ đơn giản là phương tiện số học của sự kết hợp của bốn mắt lưới. Trong những trường hợp này, chúng tôi có thể sử dụng Điểm F hoặc Điểm F1, đây là giá trị trung bình hài hòa – chính xác hơn vì nó không thay đổi nhiều đối với các giá trị cực cao. Điểm F cao hơn (tối đa 1) chỉ ra một mô hình tốt hơn.
Điểm F = 2*Chính xác*Nhắc nhở/ (Nhắc nhở + Chính xác)
Khi điều quan trọng là phải giải quyết cả kết quả dương tính giả và âm tính giả, thì điểm F1 là một thước đo tốt. Ví dụ, những người không mang virus (nhưng thuật toán đã chỉ ra rằng họ có) không cần phải cách ly một cách không cần thiết. Theo cách tương tự, những người dương tính với Covid nên được cách ly (nhưng thuật toán cho biết là không).
7. đường cong ROC
Các tham số như Độ chính xác và Độ chính xác là số liệu tốt nếu dữ liệu được cân bằng. Đối với tập dữ liệu không cân bằng, độ chính xác cao không nhất thiết có nghĩa là trình phân loại hiệu quả. Ví dụ, 90 trong số 100 sinh viên trong nhóm biết tiếng Tây Ban Nha. Bây giờ, ngay cả khi thuật toán của bạn nói rằng tất cả 100 người đều biết tiếng Tây Ban Nha, độ chính xác của nó sẽ là 90%, điều này có thể khiến bạn hình dung sai về mô hình. Đối với các bộ dữ liệu không cân bằng, các số liệu như ROC là số liệu mạnh mẽ hơn.
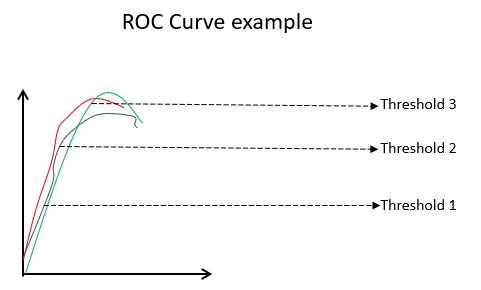 Ví dụ về đường cong ROC
Ví dụ về đường cong ROC
Đường cong ROC (Đặc tính hoạt động của máy thu) thể hiện trực quan hiệu suất của mô hình phân loại nhị phân ở các ngưỡng phân loại khác nhau. Đây là đồ thị của TPR (Tỷ lệ xác thực đúng) so với FPR (Tỷ lệ xác thực sai), được tính như sau (1-specificity) ở các giá trị ngưỡng khác nhau. Giá trị ngưỡng chính xác nhất là giá trị gần 45 độ nhất (góc trên bên trái) trong biểu đồ. Nếu ngưỡng quá cao, chúng ta sẽ không có nhiều kết quả dương tính giả, nhưng chúng ta sẽ nhận được nhiều kết quả dương tính giả hơn và ngược lại.
Nói chung, khi vẽ biểu đồ đường cong ROC cho các mô hình khác nhau, mô hình có diện tích dưới đường cong (AUC) lớn nhất được coi là mô hình tốt hơn.
Hãy tính toán tất cả các giá trị số liệu cho ma trận nhầm lẫn của Bộ phân loại I và Bộ phân loại II của chúng tôi:
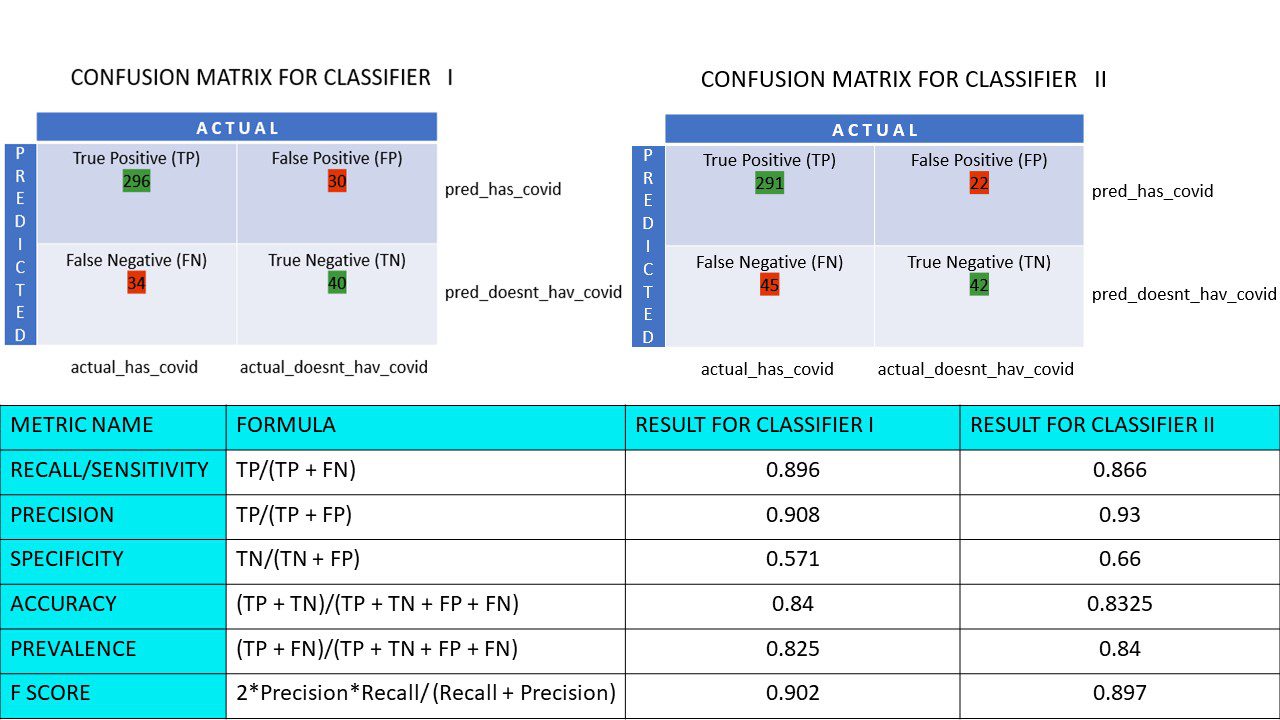 So sánh số liệu cho phân loại 1 và 2 bình chọn bánh pizza
So sánh số liệu cho phân loại 1 và 2 bình chọn bánh pizza
Chúng ta có thể thấy rằng độ chính xác cao hơn ở bộ phân loại II, trong khi độ chính xác cao hơn một chút ở bộ phân loại I. Tùy thuộc vào vấn đề, người ra quyết định có thể chọn bộ phân loại I hoặc II.
Ma trận nhầm lẫn N x N
Cho đến nay chúng ta đã thấy ma trận nhầm lẫn cho các bộ phân loại nhị phân. Điều gì sẽ xảy ra nếu có nhiều danh mục hơn là chỉ có/không hoặc thích/không thích. Ví dụ: nếu thuật toán của bạn là sắp xếp hình ảnh theo màu đỏ, lục và lam. Kiểu phân loại này được gọi là phân loại đa lớp. Số lượng biến đầu ra cũng xác định kích thước của ma trận. Vì vậy, trong trường hợp này, ma trận nhầm lẫn sẽ là 3×3.
 Ma trận nhầm lẫn cho một bộ phân loại đa lớp
Ma trận nhầm lẫn cho một bộ phân loại đa lớp
bản tóm tắt
Ma trận nhầm lẫn là một hệ thống đánh giá tuyệt vời vì nó cung cấp thông tin chi tiết về cách hoạt động của thuật toán phân loại. Nó hoạt động tốt trong cả bộ phân loại nhị phân và đa lớp, nơi cần quan tâm nhiều hơn 2 thông số. Thật dễ dàng để hình dung ma trận nhầm lẫn và chúng tôi có thể tạo tất cả các chỉ số hiệu suất khác như điểm F, độ chính xác, ROC và độ chính xác với ma trận nhầm lẫn.
Bạn cũng có thể xem cách chọn thuật toán ML cho các bài toán hồi quy.
